CS304 软件工程
Content (Deprecated)
- Lec 1. Intro
- Lec 2. Software Process & DevOps
- Lec 3. Software Requirements
- Lec 4. Version Control Systems
- Lec 5. Software Design
- Lec 6. Software Architecture
- Lec 7. Build & Dependency Management
- Lec 8. Software Documentation
- Lec 9. Software Testing
- Lec 10. Continuous Integration
- Lec 11. Continuous Deployment
- Lec 12. Software Quality & Metrics
- Lec 13. Software Evolution & Maintenance
- Lec 14. AI in Software Engineering
Lec 1. Introduction
What is Software ? (Artifacts)
- Source code
- Tests
- Documentation
- Build scripts
- Configurations
- Executables (.exe etc.)
- …
How to build a software ?
- Programming is a significant part of software engineering
- Programming is how you generate a new software in the first place
- Building a software is programming integrated over time, scale, and trade-offs
What’s software engineering ?
Software Crisis
- Over-budget, over-time
- Inefficient or low quality
- Not meet requirement
- Difficult to maintain
- Never delivered
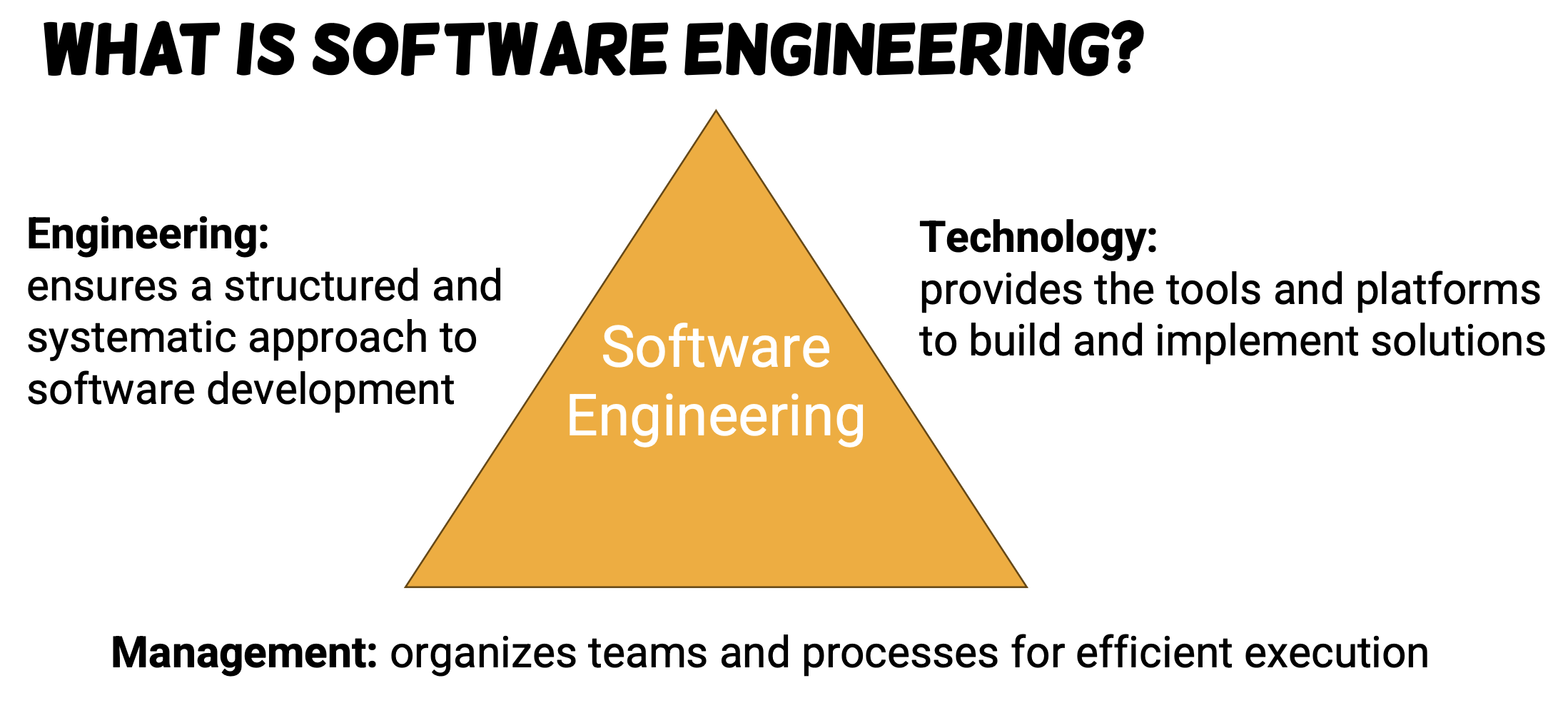
Def. Software engineering is the branch of engineering that deals with the design, development, testing, and maintenance of software applications, while ensuring that the software to be built is:
- Correct
- Consistent
- On budget
- On time
- Align with the requirements.
Objective of SE ?
- Quality: improve the quality of software
- Efficiency: improve the efficiency of building software
What’s in SE progress ? (Dev&Ops)
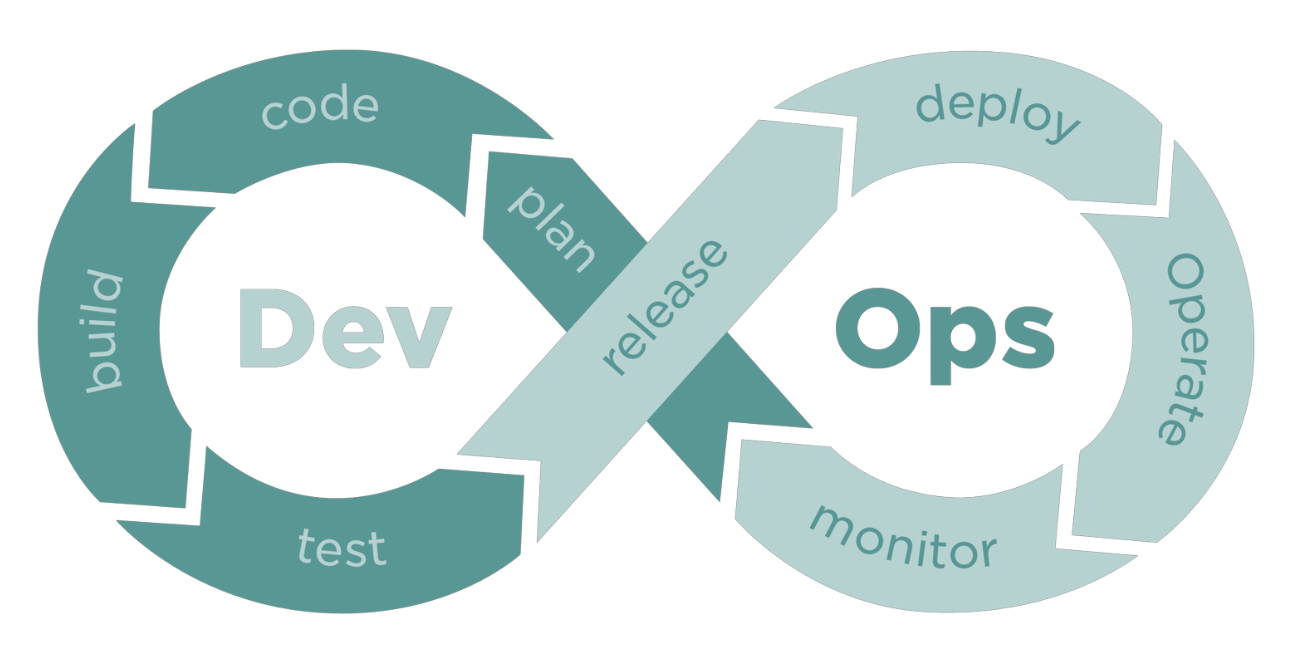
- And all the objectives are to improve quality and efficiency !
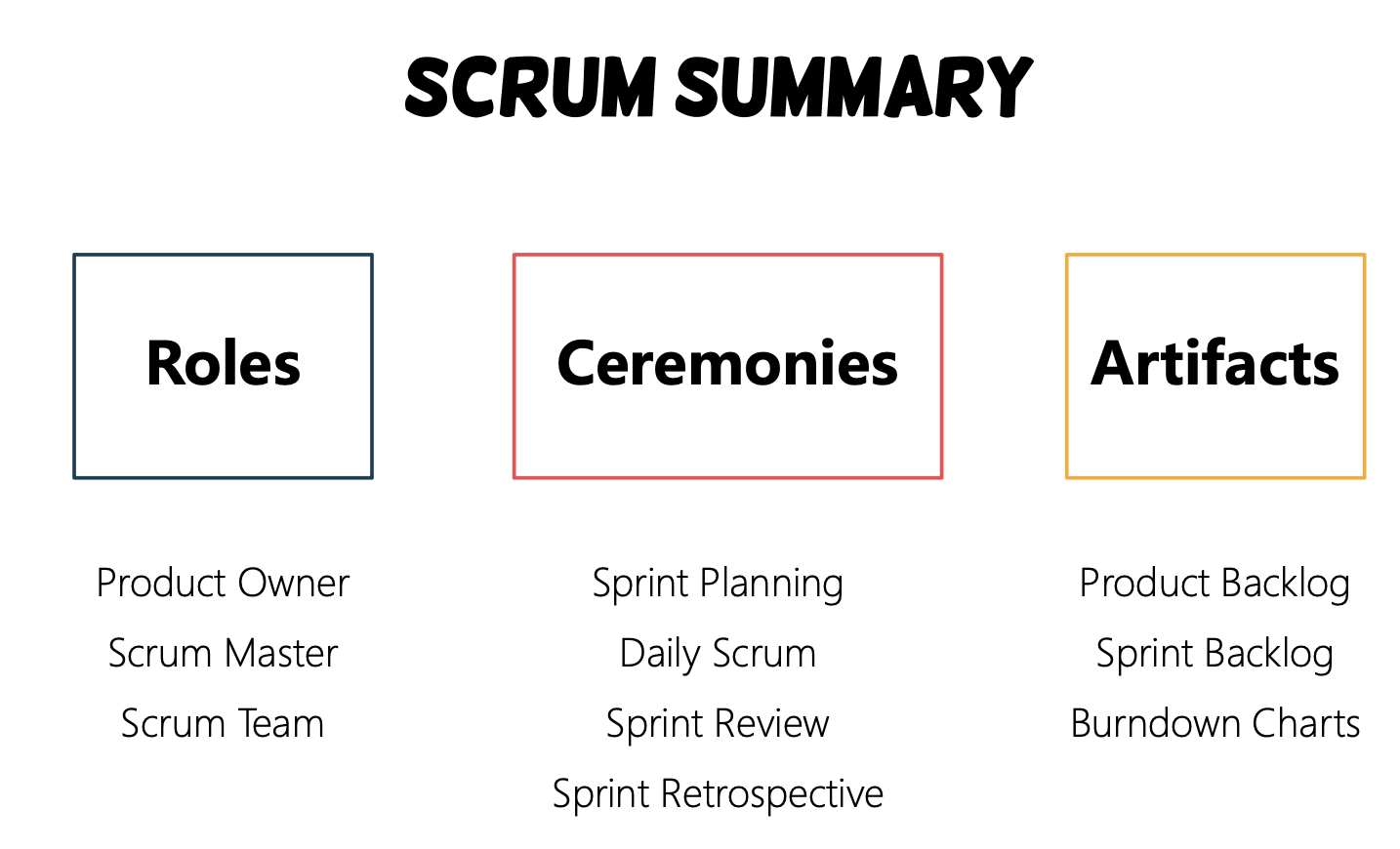
Lec 2. Software Process & DevOps
Overview
- Process model
- Agile & Scrum
- DevOps
Intro
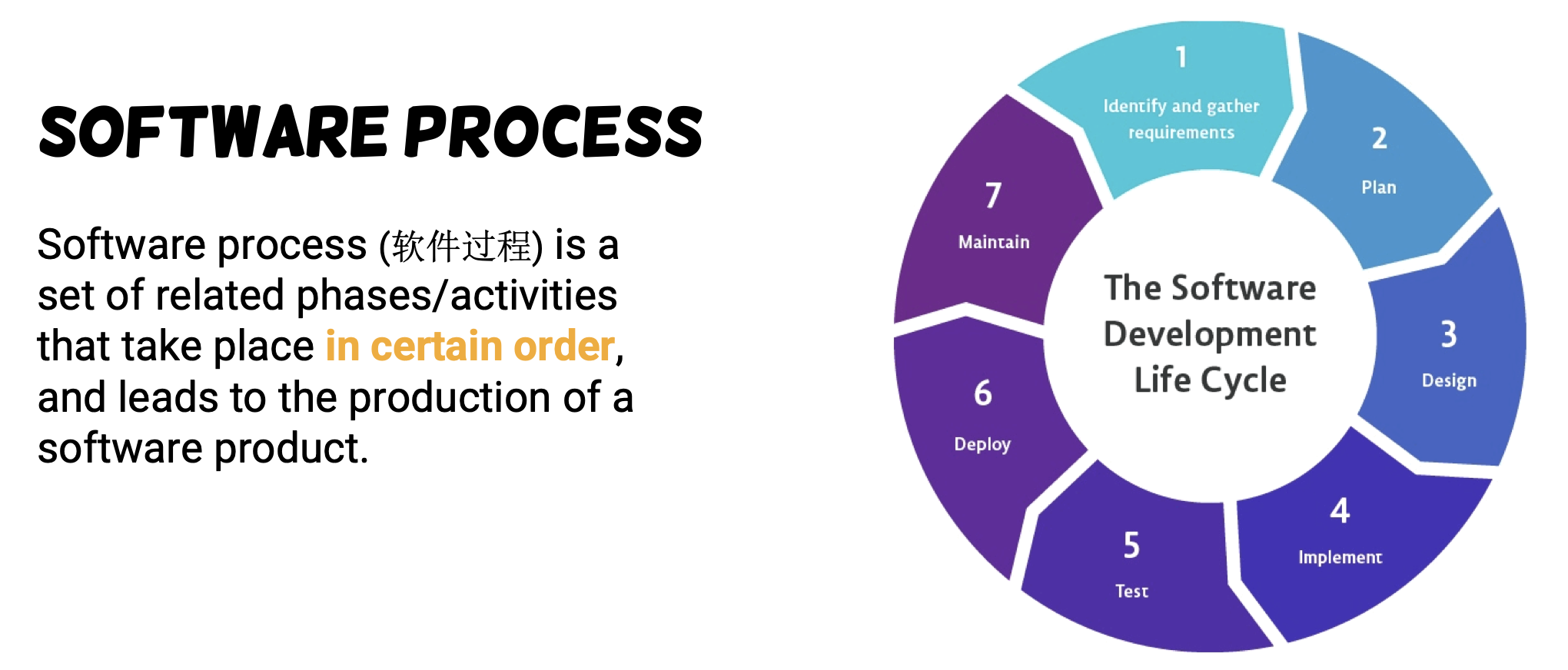

How to build software process ?
- Software process models (or software lifecycle model) were originally proposed to bring order to the chaos of software development, it determines:
- The order of these phases
- The criteria for transition of each phase

What is agile ?
the ability to create and respond to change.
Process Model
Waterfall model
Def. The waterfall model is a sequential and linear approach for software development process.
- No overlap between phases.
- result of each phase is one or more documents that are approved
- Problems: adapted only when requirements are well defined and reasonably stable.
Incremental Process Model
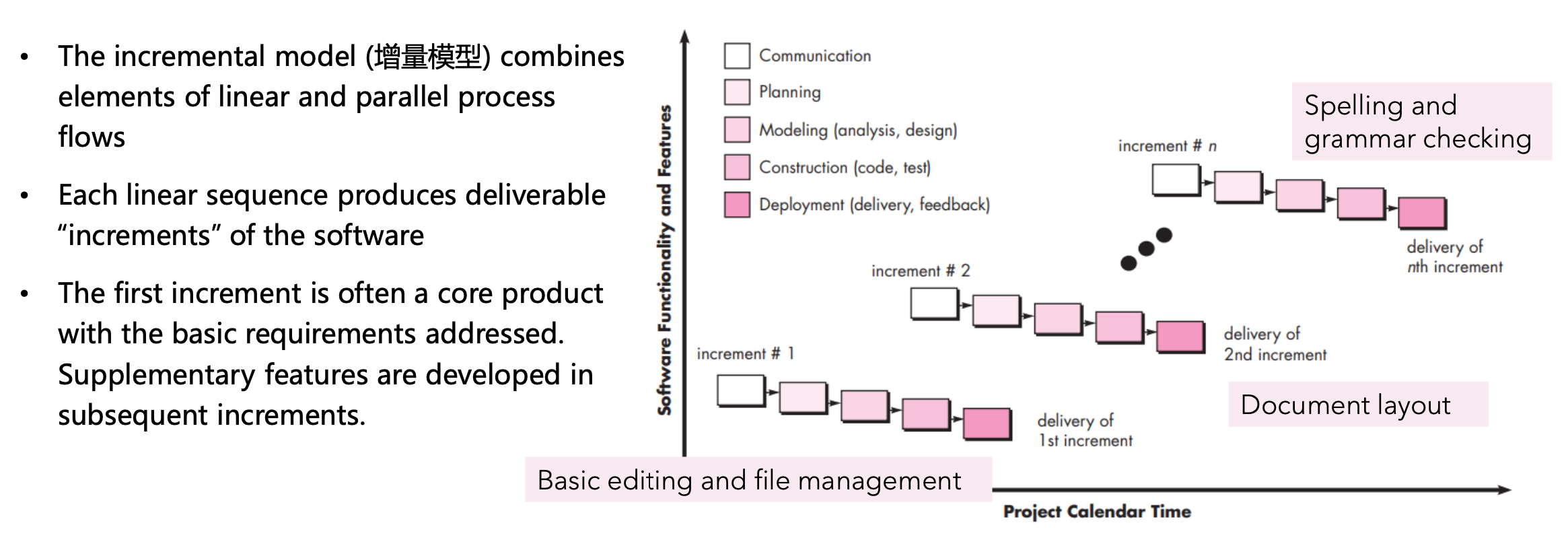
- Pros
- Reducing cost due to requirement changes
- Easier to get customer feedback and adapt
- Easier to test and debug during a smaller iteration
- More rapid delivery and deployment of useful software
- Particularly useful when staffing is unavailable for a complete implementation
- Cons
- Needs good planning and design of the whole system before breaking it down for incremental builds
- System structure tends to degrade as new increments are added. Unless effort is spent on refactoring to improve the software, regular change tends to corrupt its structure. [项目结构不稳定]
- Incorporating further software changes becomes increasingly difficult and costly. [额外开发费时费力]
Evolutionary Process Model
- Early evolutionary process models: prototyping and the spiral model
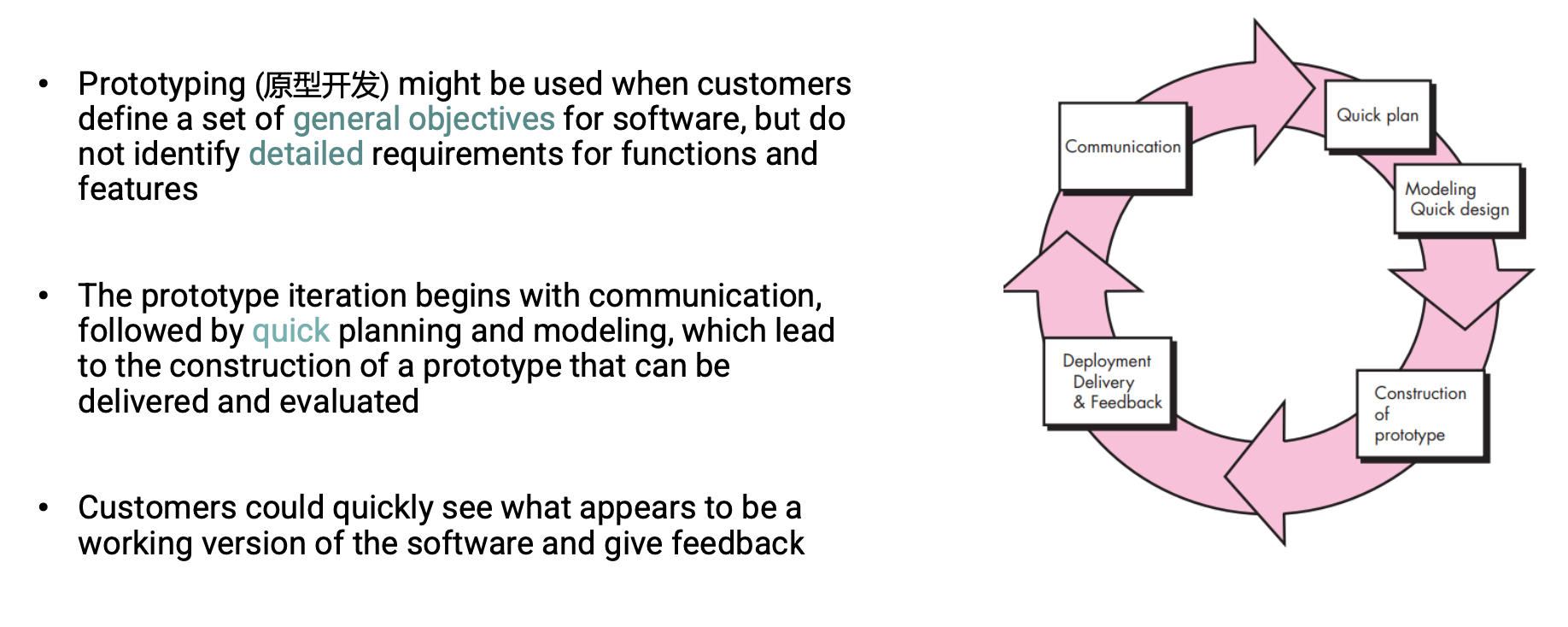
- Developers often make implementation compromises, e.g., inappropriate OS, PL, and inefficient algorithms, in order to get a prototype working quickly
- The prototype is often discarded (at least in part), and the actual software is engineered with an eye toward quality.
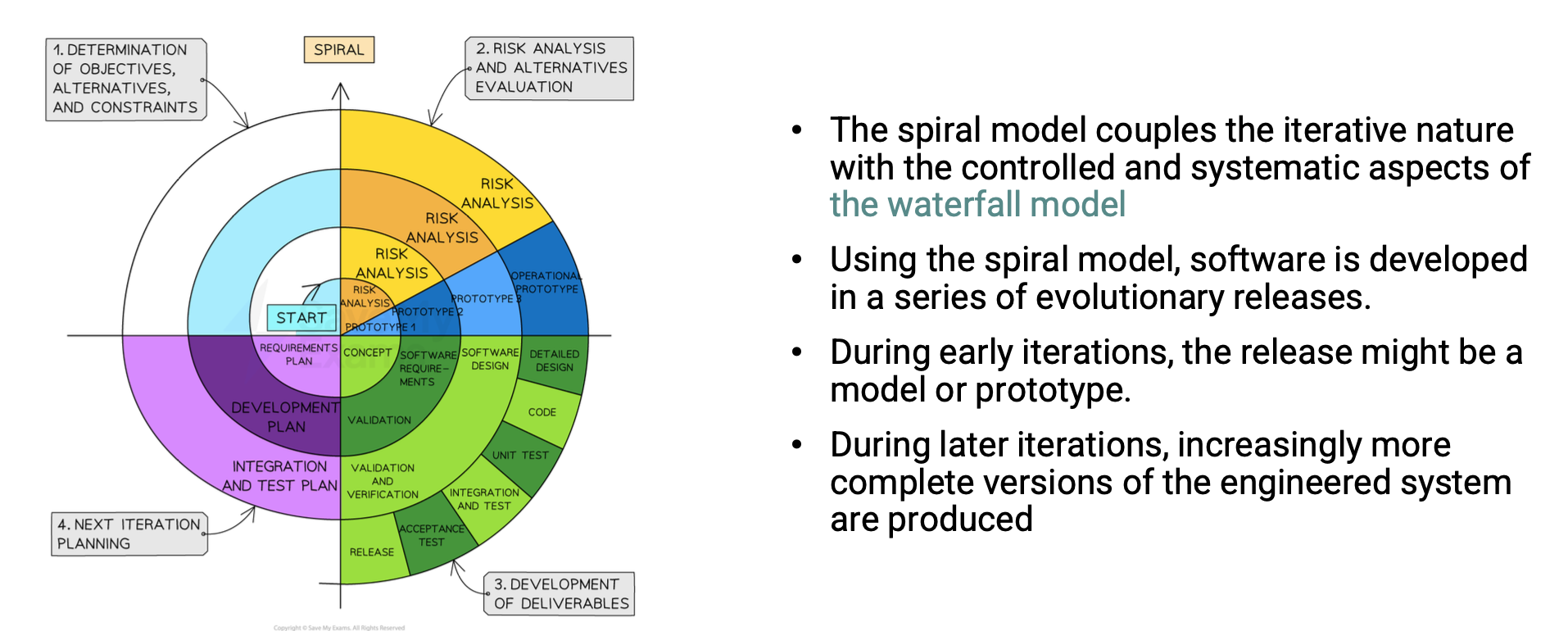
- Pros
- Effectively reducing potential risks
- Features can be updated because of the iterative nature
- Better for high-risk project, e.g., banking, medical systems
- Cons
- Risk analysis highly rely on experts
- Complex and costly
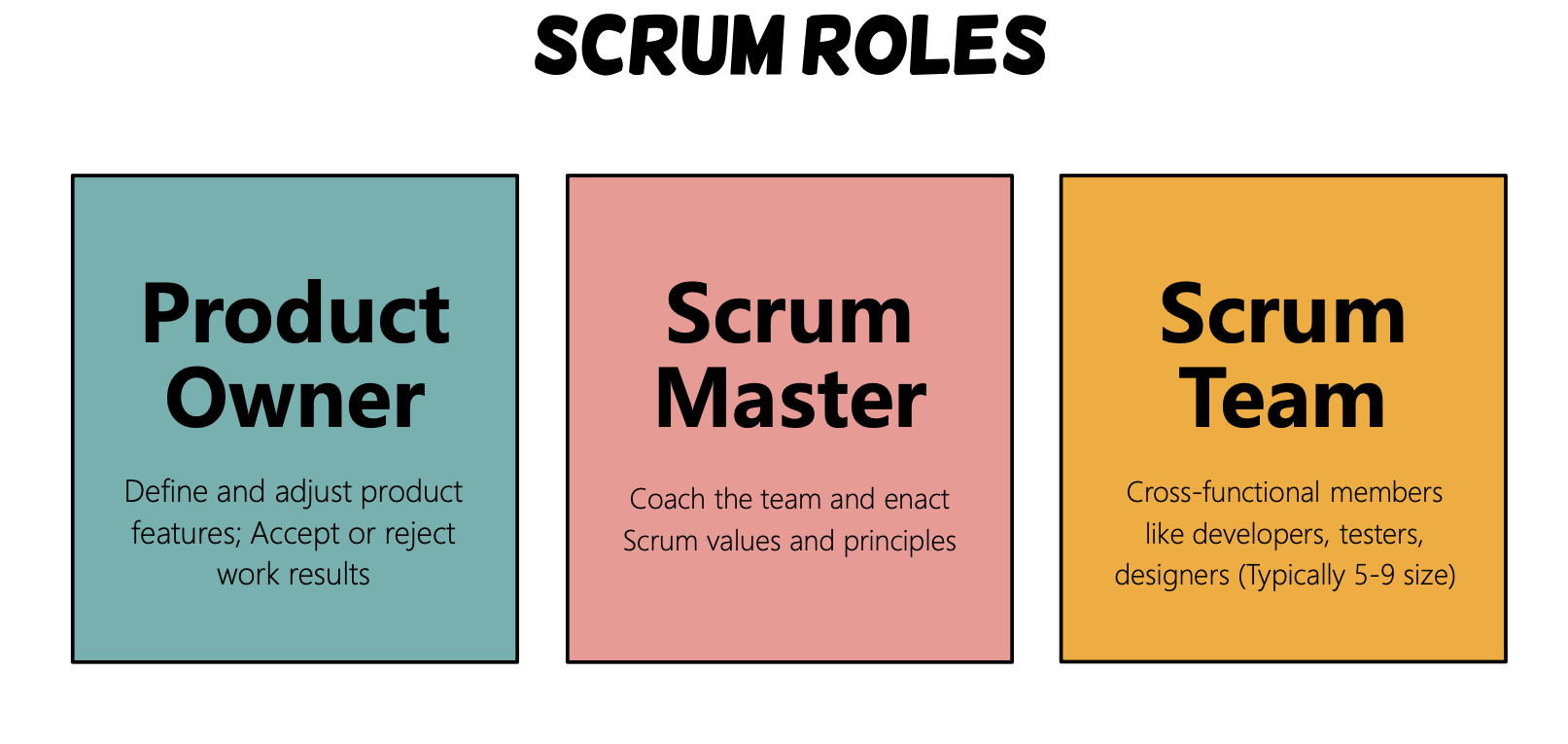
Agile & Scrum
Concepts
- agile: 一种敏捷开发的思维方式/思路
- scrum: 基于 agile 的具体方法论,提供了一套明确的规则、角色和工作流程,帮助团队有效地实施Agile原则:
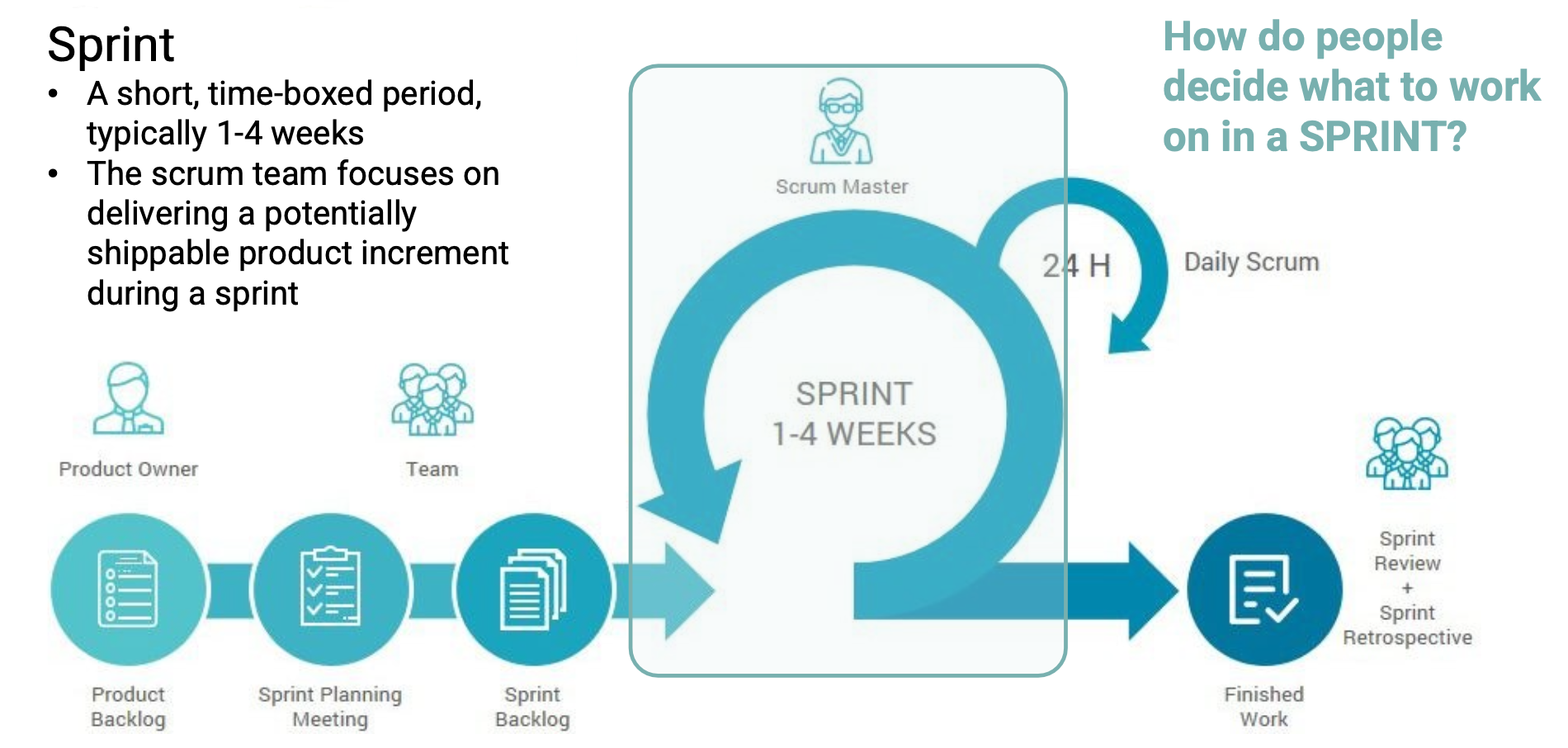
- Sprint
- TODOLists / ScrumBoard
- Daily Scrum
- Sprint Retrospective, etc.

DevOps
Key principles
- Collaboration: Bridges the gap between developers and IT operations.
- Automation: Automates builds, testing, and deployments.
- Monitoring & Feedback: Uses real-time monitoring to improve system performance and user experience.
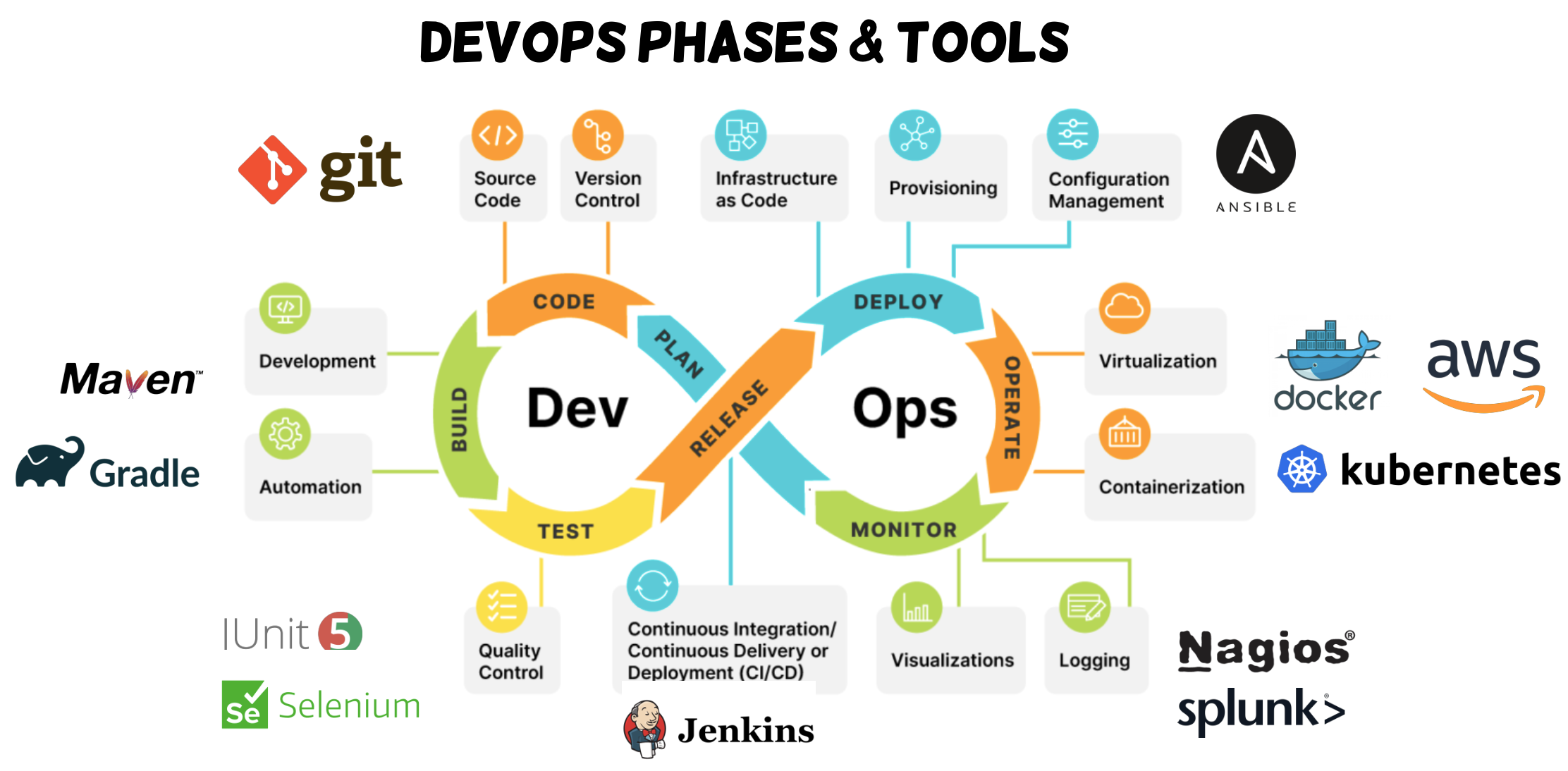
Benefits
- Faster software releases
- Faster feedback
- Improved system reliability and stability
- Reduced deployment failures and rollback times
- Increased efficiency and resource utilization
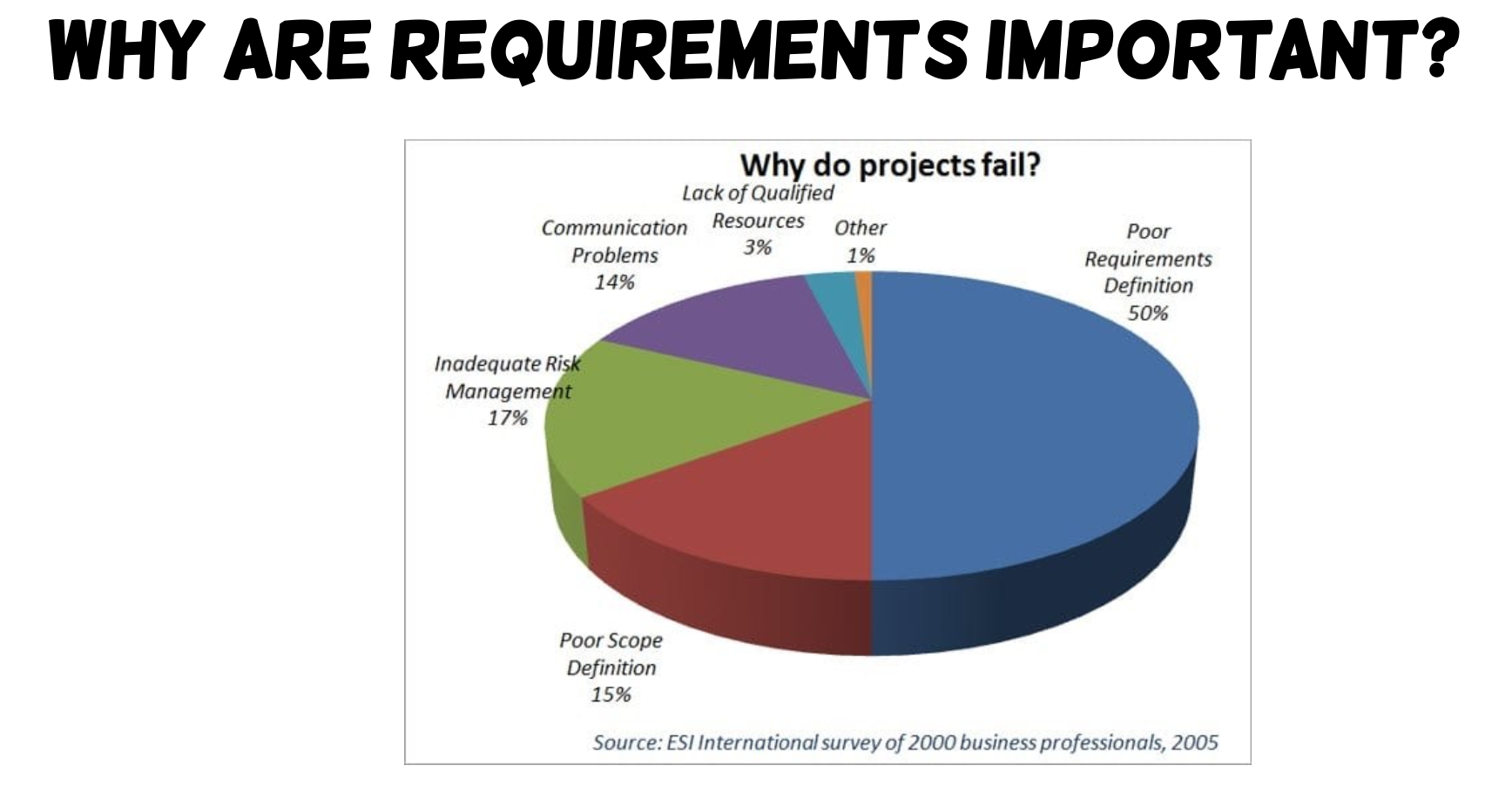
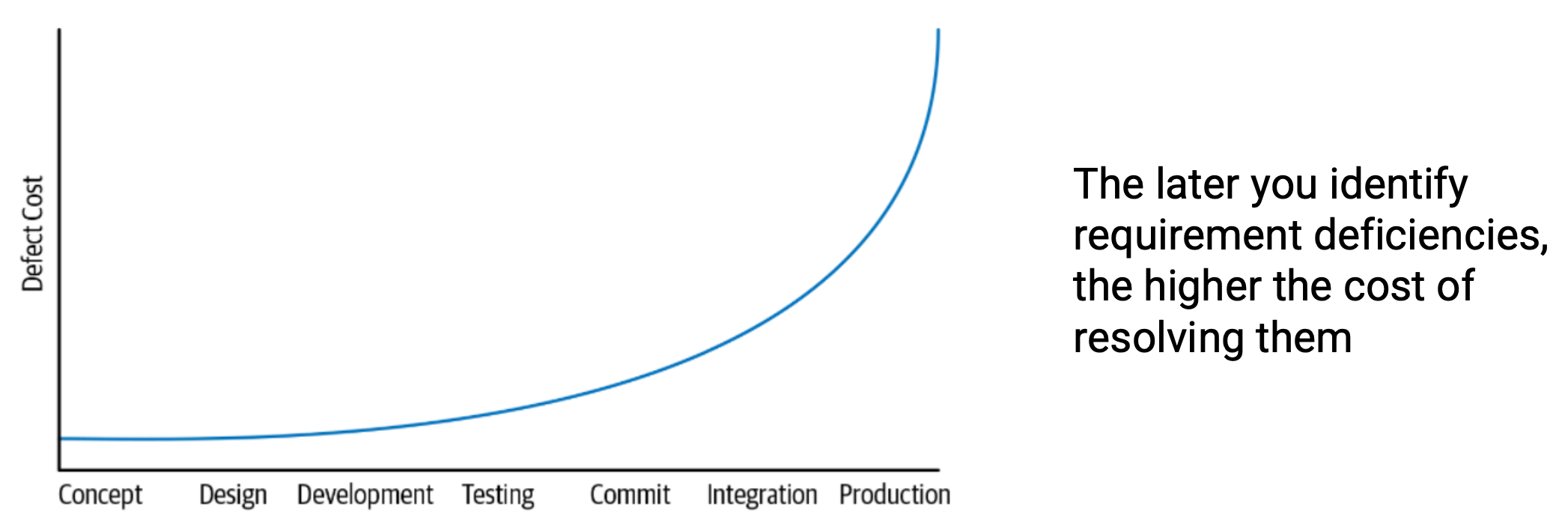
Lec 3. Requirement
Overview of software requirements
- Software requirements (需求) describe the following:
- what the system should do
- the services that it provides
- the constraints on its operation
Stakeholders [利益相关者]
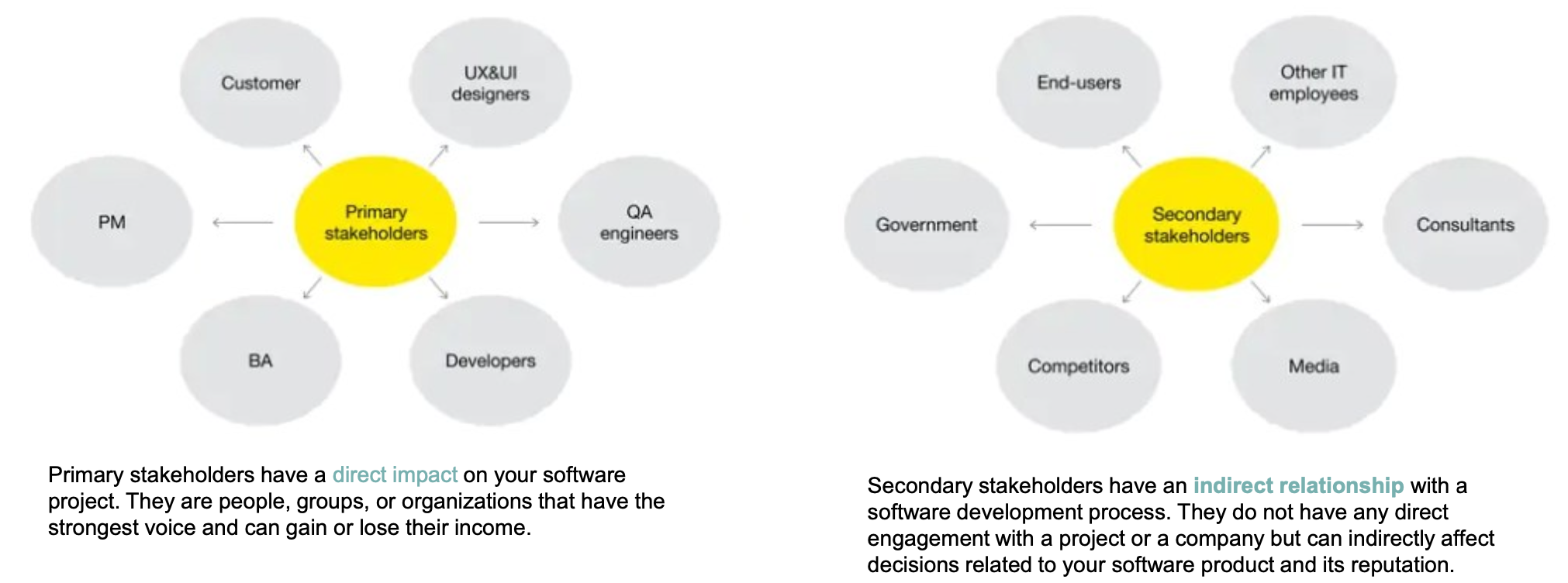
Types of requirements
Classification of Softward Requirements
- Business View: Why is the project needed? [WHY?]
- outline a general overview of a product
- primary usage
- why it is needed
- scope and vision, etc.
- outline a general overview of a product
- User View: What do users need the system to do? [WHO?]
- User requirements are gathered using use case, user scenarios, and user stories
- written in natural languages with little/no technical details
- System View: What Does the system need to do? [HOW?]
- describe software as functional modules and non-functional attributes.
- written for developers with more formal format
Functional Requirements
- Functional requirements are basic functionalities that the system should offer.
- They are represented or stated in the form of input to be given to the system, the operation performed and the output expected.
- Functional requirements are basically the requirements stated by the user which one can see directly in the final product.
e.g. ⬇️

Non-Functional Requirements
- Non-functional requirements are not related to the software’s functional aspect
- Non-functional requirements specify the software’s quality attribute.
- Non-functional requirements define the general characteristics, behavior of the system, and features that affect the experience of the user.
e.g. ⬇️

Requirements analysis in Scrum
User Story
- The product owner is responsible for talking to all stakeholders and gathering requirements.
- Based on the gathered information, the scrum team work together to come up with user stories, which are simple sentences that describe what the users need
Then what after a user story ?
From user story to tasks
- Tasks are used to break down user stories even further.
- Tasks are the smallest unit used in scrum to track work.
- A task should be completed by one person on the team
- A task typically takes ~1 day
How to prioritize user stories?
A MoSCoW Model.
- MUST HAVE (M): Non-negotiable product needs that are mandatory for the team
- SHOULD HAVE (S): Important initiatives that are not vital, but add significant value
- COULD HAVE ©: Nice to have initiatives that will have a small impact if left out
- WILL NOT HAVE(W): Initiatives that are not priority for this specific time frame
How do we know if a user story is complete?
- In agile, acceptance criteria refer to set of predefined requirements that must be met to mark a user story complete.
- A product owner may be responsible for writing acceptance criteria for the stories in the product backlog

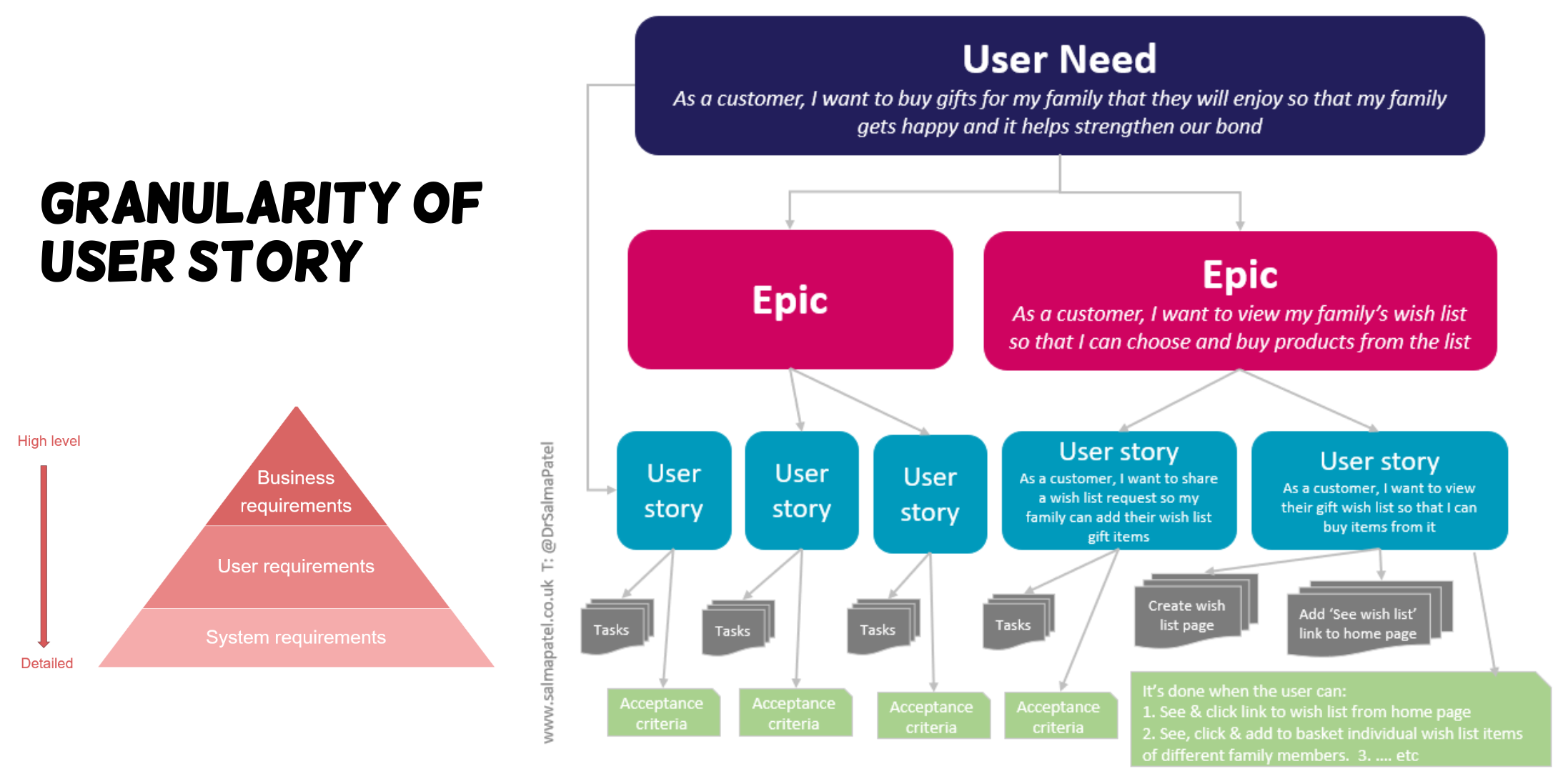
Lec 4. Version Control System
Overview of VCS
- Version control systems (VCS) are software tools that help software teams track and manage modifications to artifacts (typically source code) over time.
- Revisit older versions
- Revert selected files back to a previous state and recover from mistakes
- Compare changes over time
- Diagnosing: see who last modified something that might be causing a problem, who introduced an issue and when, and more.
- VCS are especially useful for DevOps teams since they help them to reduce risks caused by continuous changes and increase successful deployments.
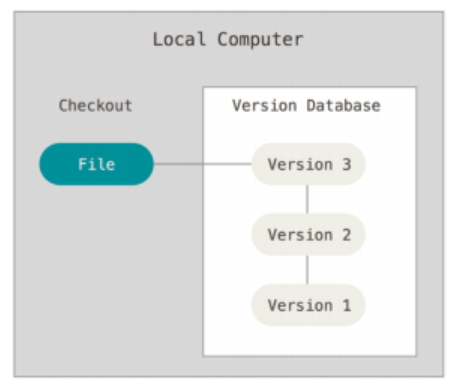
Local & Centralized VCS
-
Representative local VCS(RVCS): keeping patch sets in a special format on disk
-
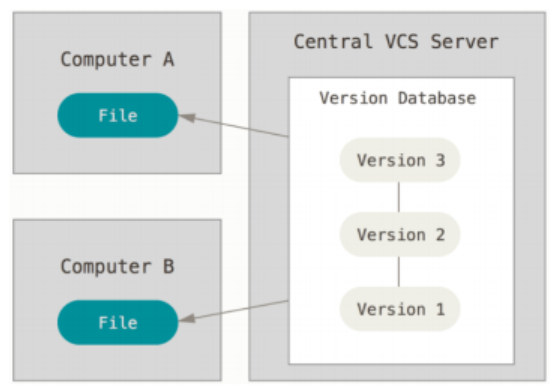
Centralized VCS emerged since developers need to collaborate with each other
-
Centralized VCS (e.g., CVS, Subversion/SVN) have a single server that contains all the versioned files; clients check out files from that central place.
 |
 |
Distributed Version Control System
- In a Distributed VCS (e.g., BitKeeper, git, Mercurial), clients don’t just check out the latest snapshot of the files.
- Rather, they fully mirror the repository, including its full history. Every clone is really a full backup of all the data.
- Thus, if any server dies, and these systems were collaborating via that server, any of the client repositories can be copied back up to the server to restore it.
Git Basic
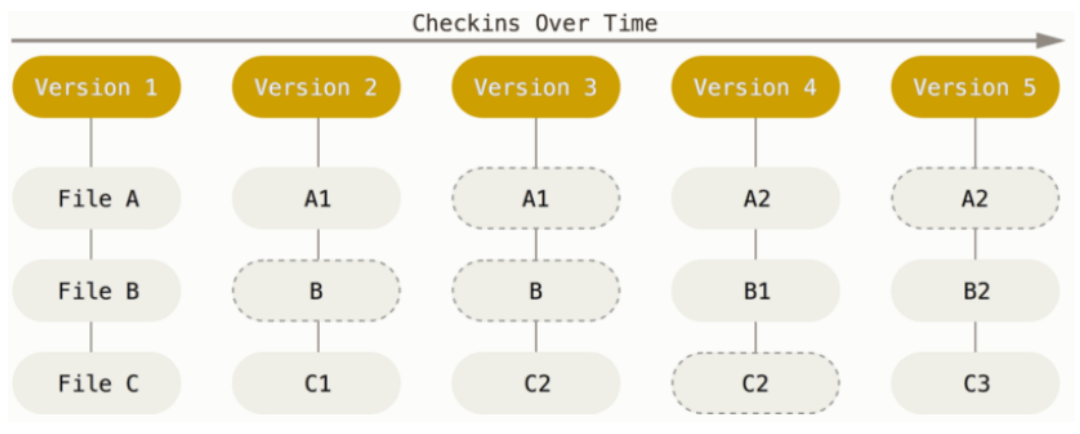
Snapshot
- The major difference between Git and any other VCS is the way Git thinks about its data.
- Conceptually, most other systems store information as a list of file-based changes.
- These other systems (e.g., CVS, SVN, Perforce) think of the information they store as a set of files and the changes made to each file over time (this is commonly described as delta-based version control).
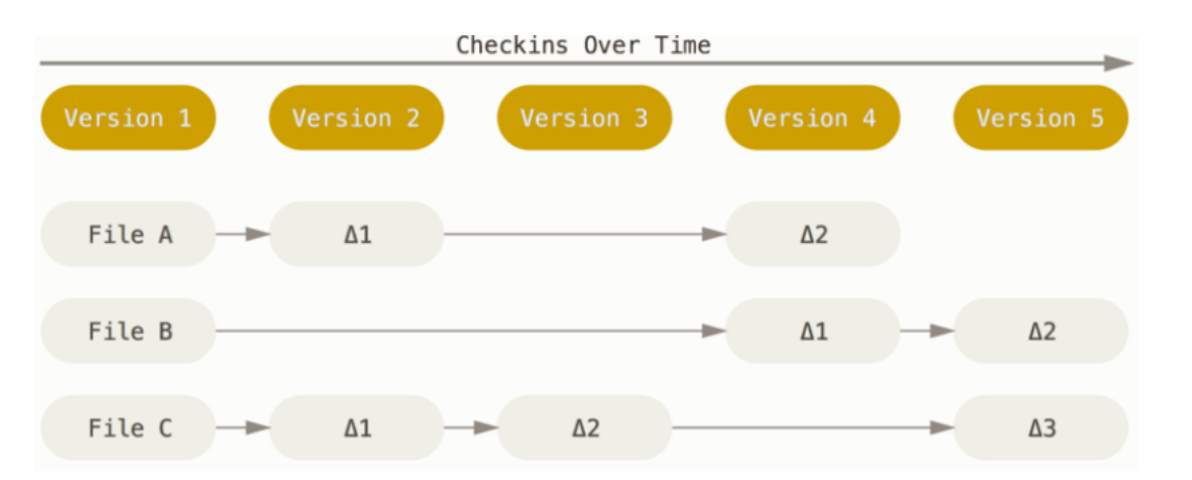
- Git thinks of its data more like a series of snapshots of a miniature filesystem.
- With Git, every time you commit, or save the state of your project, Git basically takes a picture of what all your files look like at that moment and stores a reference to that snapshot.
- To be efficient, if files have not changed, Git doesn’t store the file again, just a link to the previous identical file it has already stored.
- Git has integrity
- Everything in Git is checksummed before it is stored and is then referred to by that checksum.
- It’s impossible to change the contents of any file or directory without Git knowing about it.
- The mechanism that Git uses for this checksumming is called a SHA-1 hash. This is a 40-character string composed of
HEXcharacters and calculated based on the contents of a file or directory structure in Git. - Git stores everything in its database not by file name but by the hash value of its contents.
- Git generally only adds data
- When you do actions in Git, nearly all of them only add data to the Git database
- It is hard to get the system to erase data in any way.
- After you commit a snapshot into Git, it is very difficult to lose, especially if you regularly push your database to another repository.
Git Architecture
Git Local Repo: Workflow
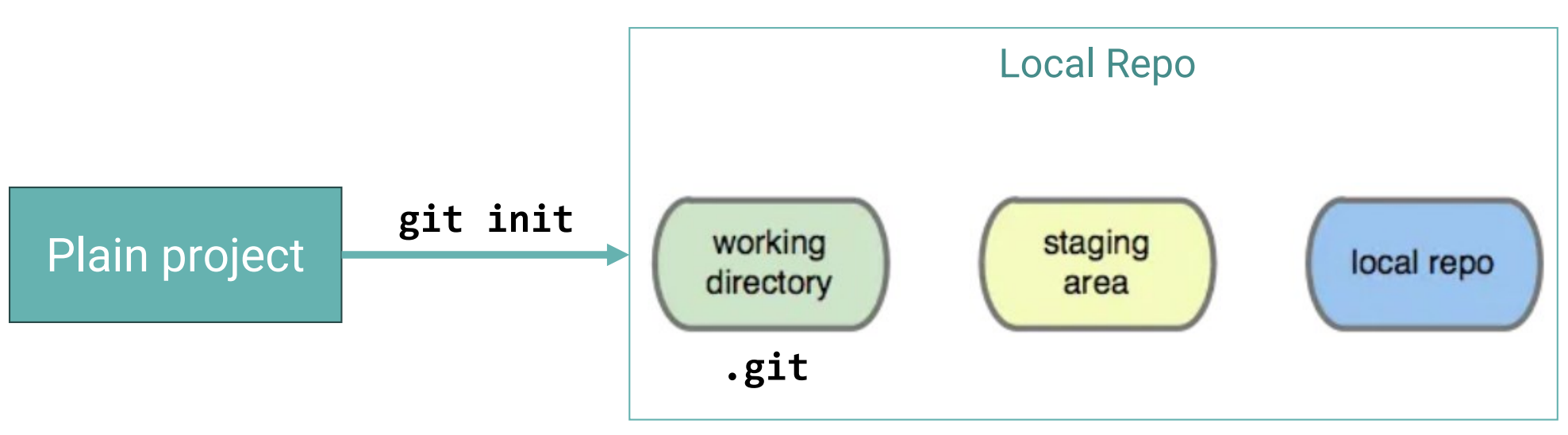
- Untracked files are the ones still NOT versioned—”tracked”—by Git. This is the state of new files you add to your repository.
- Git is aware the file exists, but still hasn’t saved it in its internal database.
- If you lose the information from an untracked file, it’s typically gone for good. Git can’t recover it since it didn’t store it in the first place.
- Staging area: a file in your Git directory, that stores information about what will go into your next commit.
- Untracked: files not tracked by Git (
git addto next stage) - Staged: means that you have marked a modified file in its current version to go into your next commit snapshot. (
git committo next stage) - Committed: means that the data is safely stored in your local database. (
git pushto update version) - Modified: means that you have changed the file but have not committed it to your database yet. (
git committo next stage)
- Untracked: files not tracked by Git (
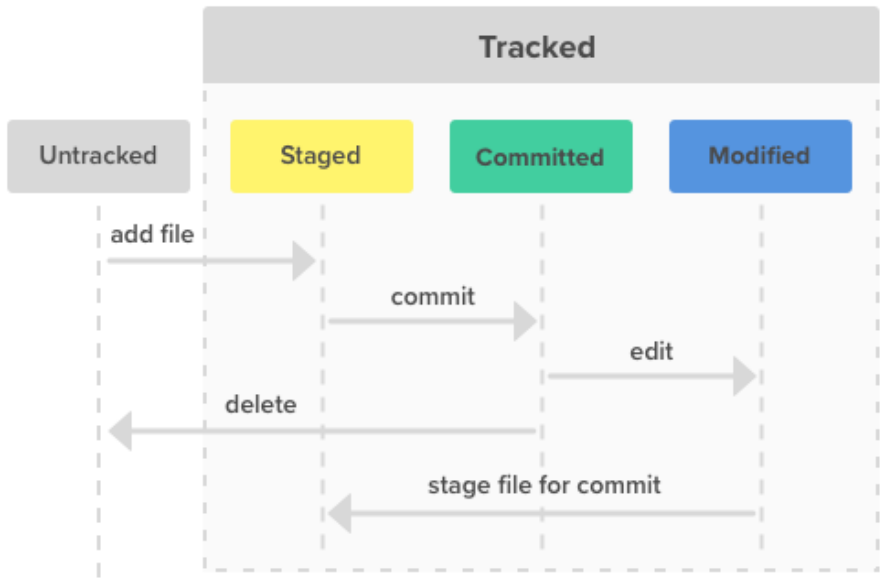
3 Sections
- Working tree: a single checkout of one version of the project. These files are pulled out of the compressed database in the Git directory and placed on disk for you to use or modify.
- Staging area (index): a file in your Git directory, that stores information about what will go into your next commit.
- Git directory: where Git stores the metadata and object database for your project. This is what is copied when you clone a repository from another computer.
Git Remote Repo
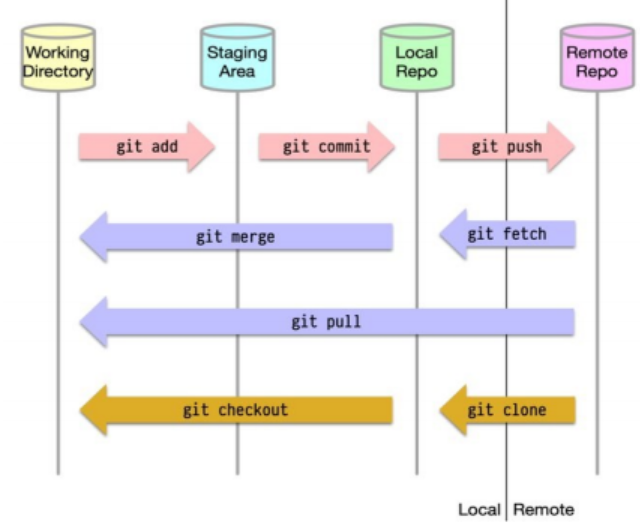
Git Internals
-
3 Components inside
.git- Objects: content of files, directories, commits, and tags, identified by SHA-1 hash, stored in
.git/objects/ - References: A branch, remote branch or a tag, which is simply a pointer to an object, stored in plain text in
.git/refs/ - Index: a staging area, stored as a binary file in
.git/index.
- Objects: content of files, directories, commits, and tags, identified by SHA-1 hash, stored in
-
Types of Git Objects
- Blob: file content, identified by a hash
- Tree: list of pointers to blob (file), or tree (directory), identified by a hash
- Commit Object:
- Reference to the top-level tree for the snapshot of the project at that point
- Parent commit (if any)
- Author info, commit message, etc.
- Tag Object: name associated with a commit
Git Branching
1 | git branch <branch> # create |
- Example of merging branch:
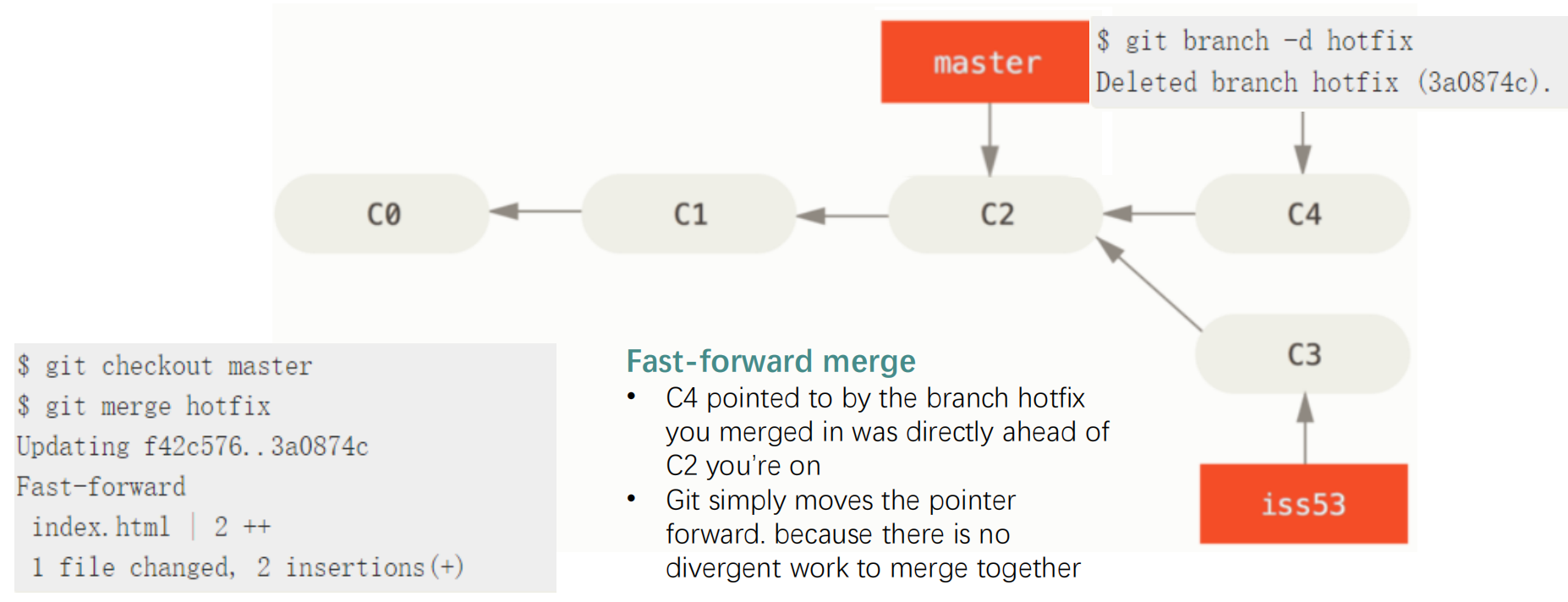
1 | git checkout main # switch to branch main |
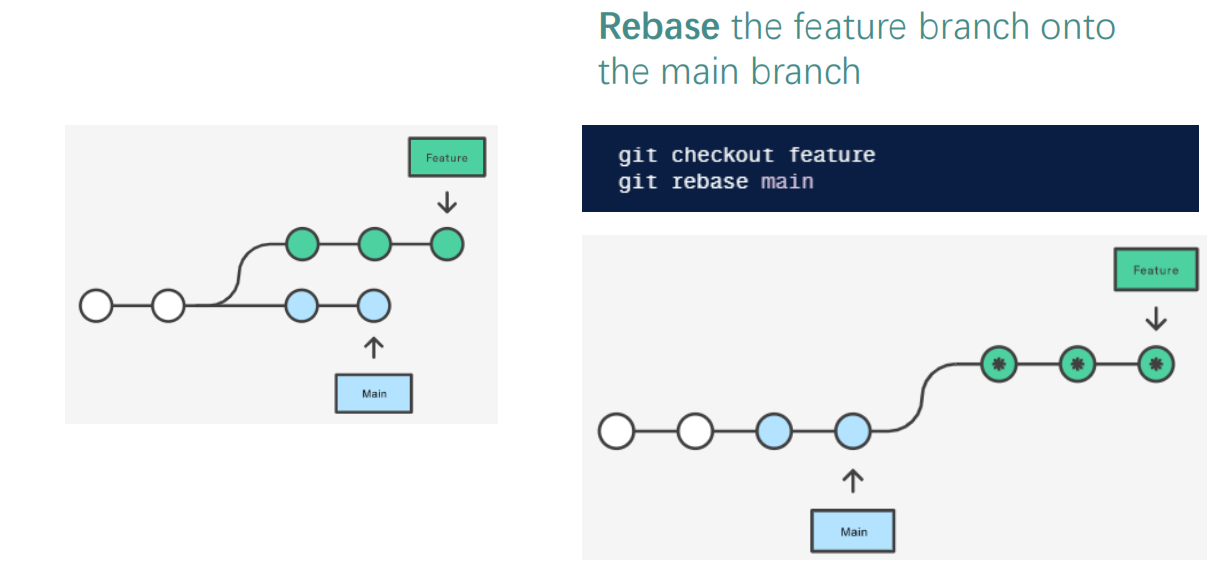
Git Merge vs. Rebase
How to solve conflicts ?
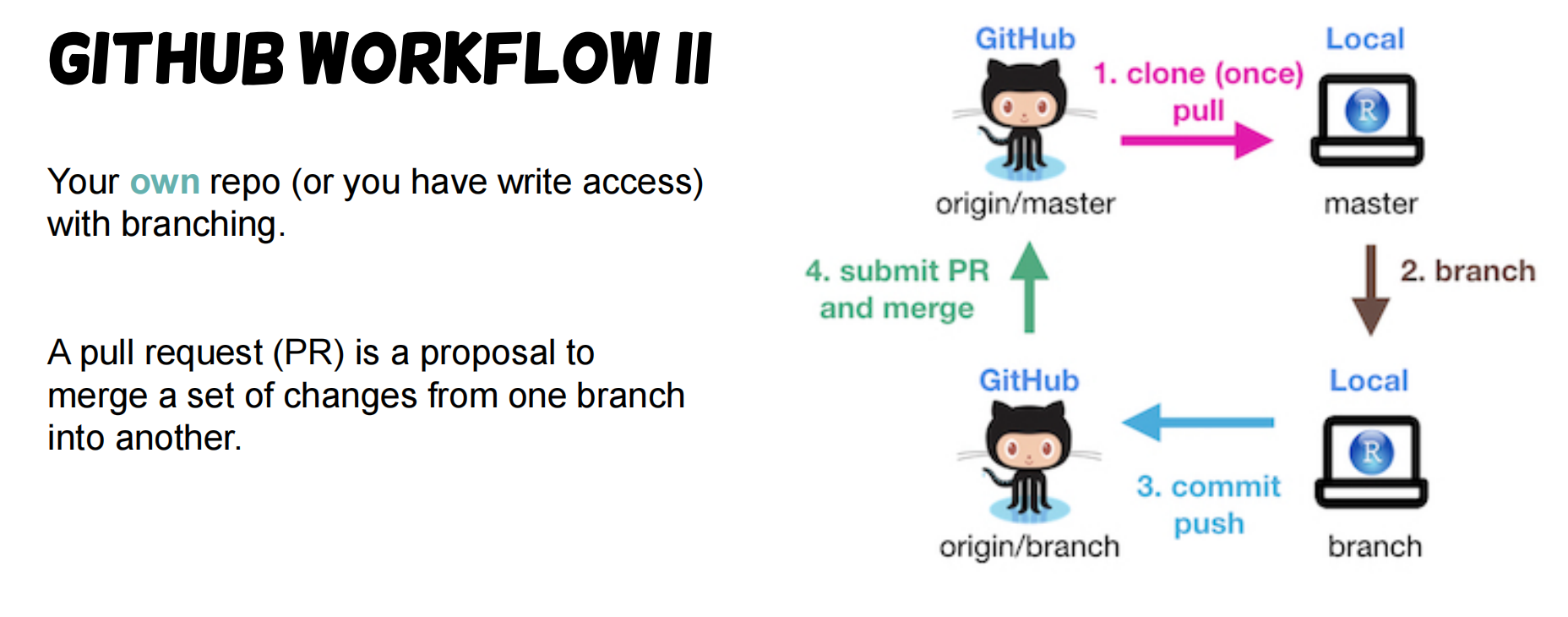
Github Workflow

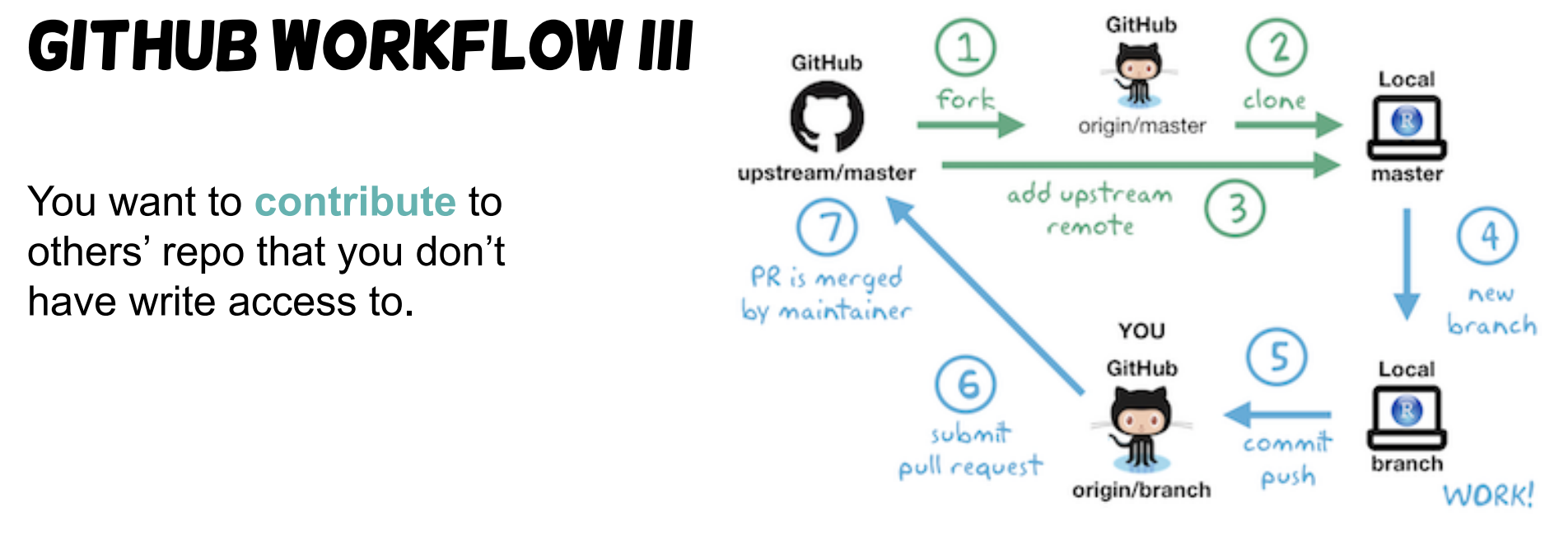
- Git clone vs. fork
- Any public git repository can be forked or cloned
- Key difference: how much control and independence you want over the codebase once you’ve copied it.
- Clone: a clone creates a linked copy that will continue to synchronize with the target repository.
- Fork: A fork creates a completely independent copy of Git repo, disconnecting the codebase from previous committers.
Lec 5. Software Design & Architecture
Where we’re in?
Code: Design
Architectural design
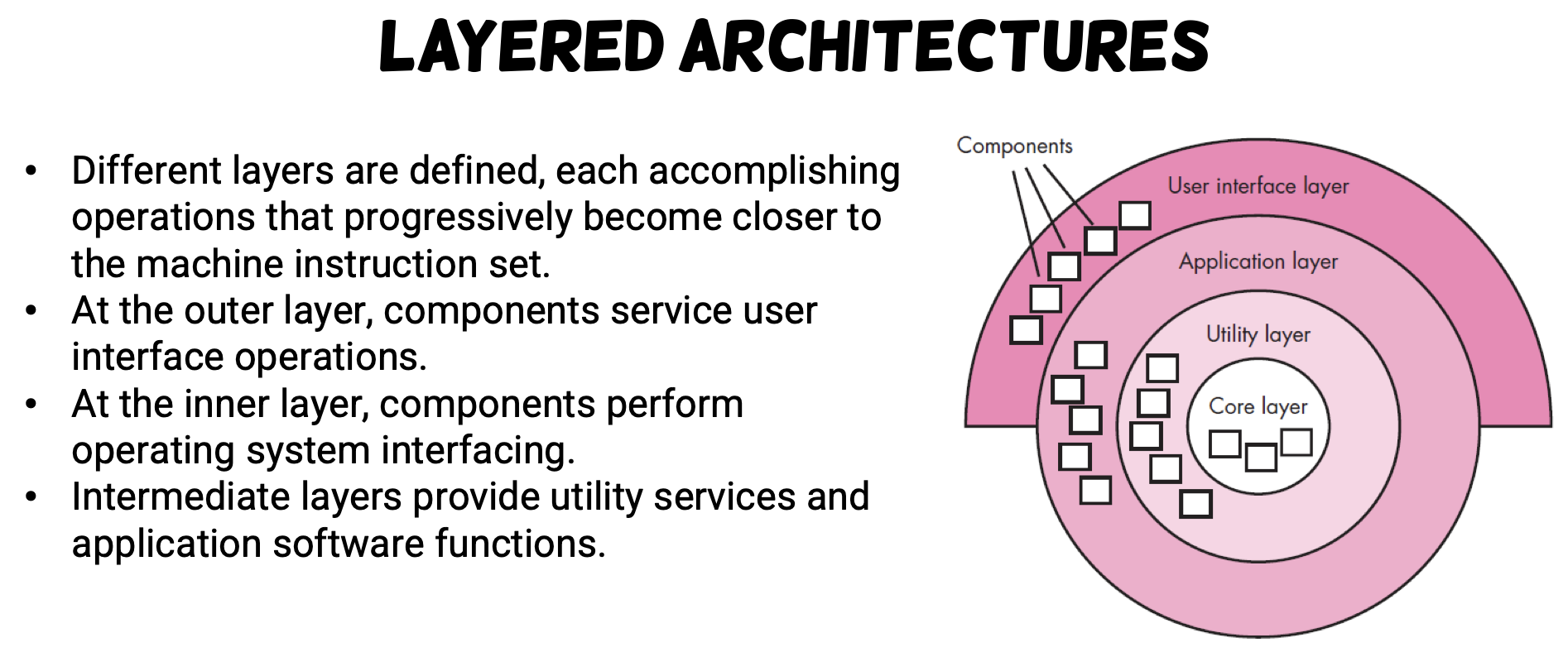
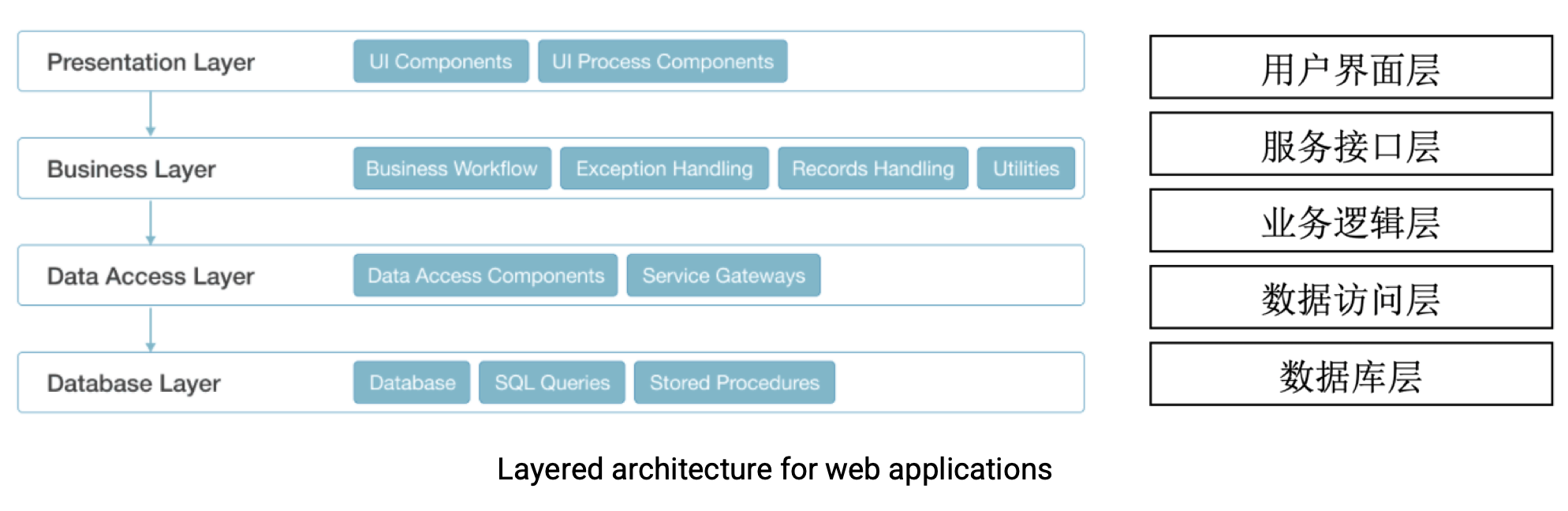
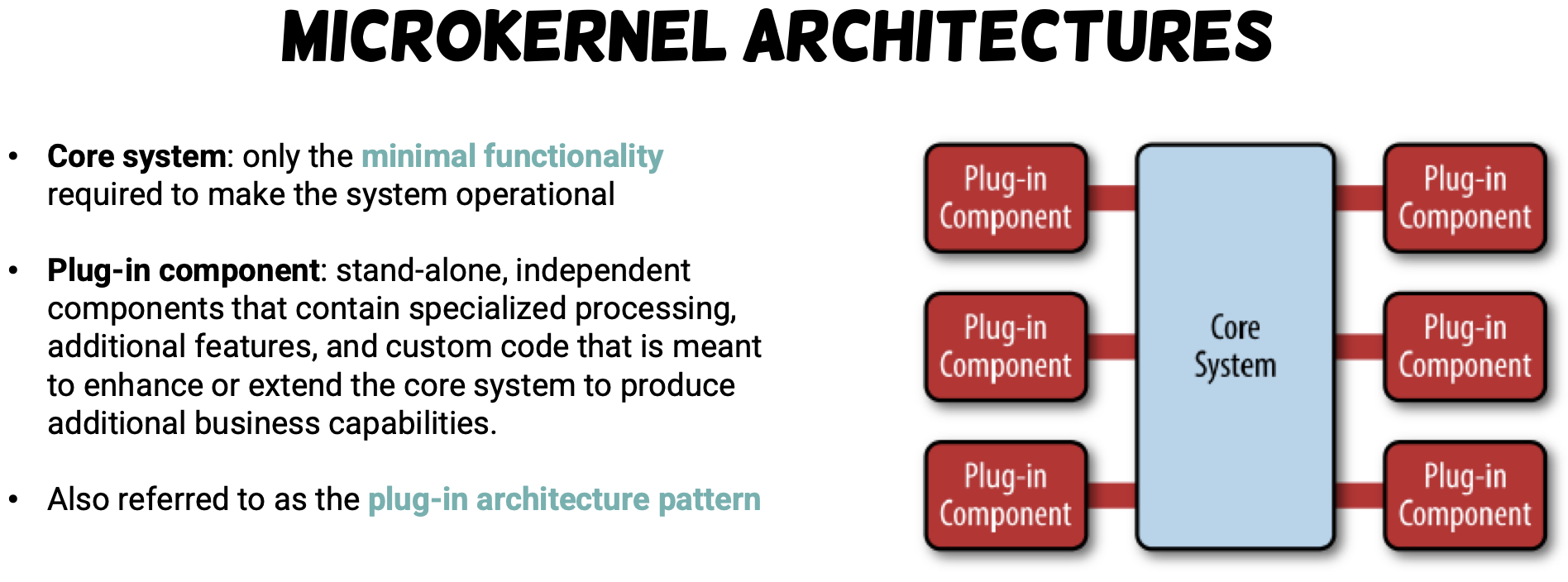
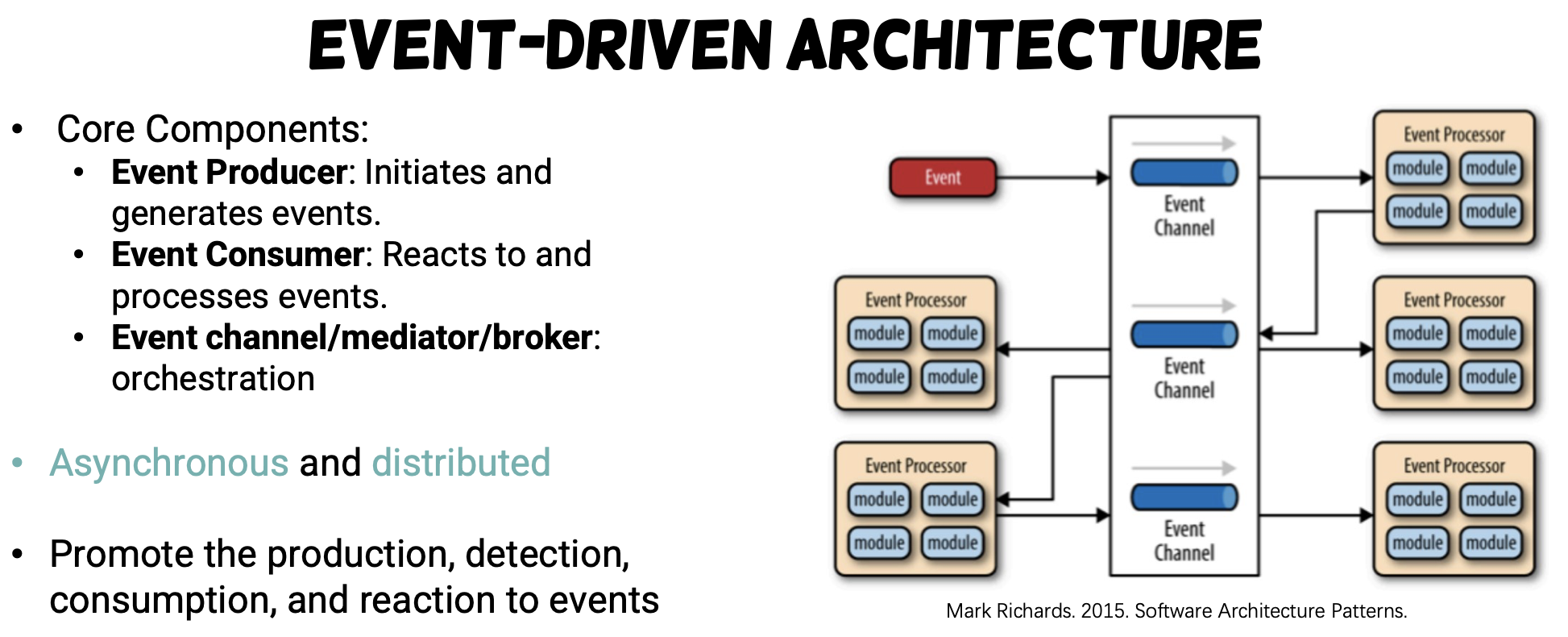
Software Architectural Style
- Classic, Monolithic
- Data-centered architecture
- Data-flow architecture
- Call-and-return architecture
- Object-oriented architecture
- Layered architecture
- Service-based, Distributed, DevOps
- Microkernel architecture
- Event-driven architecture
- Microservice architecture
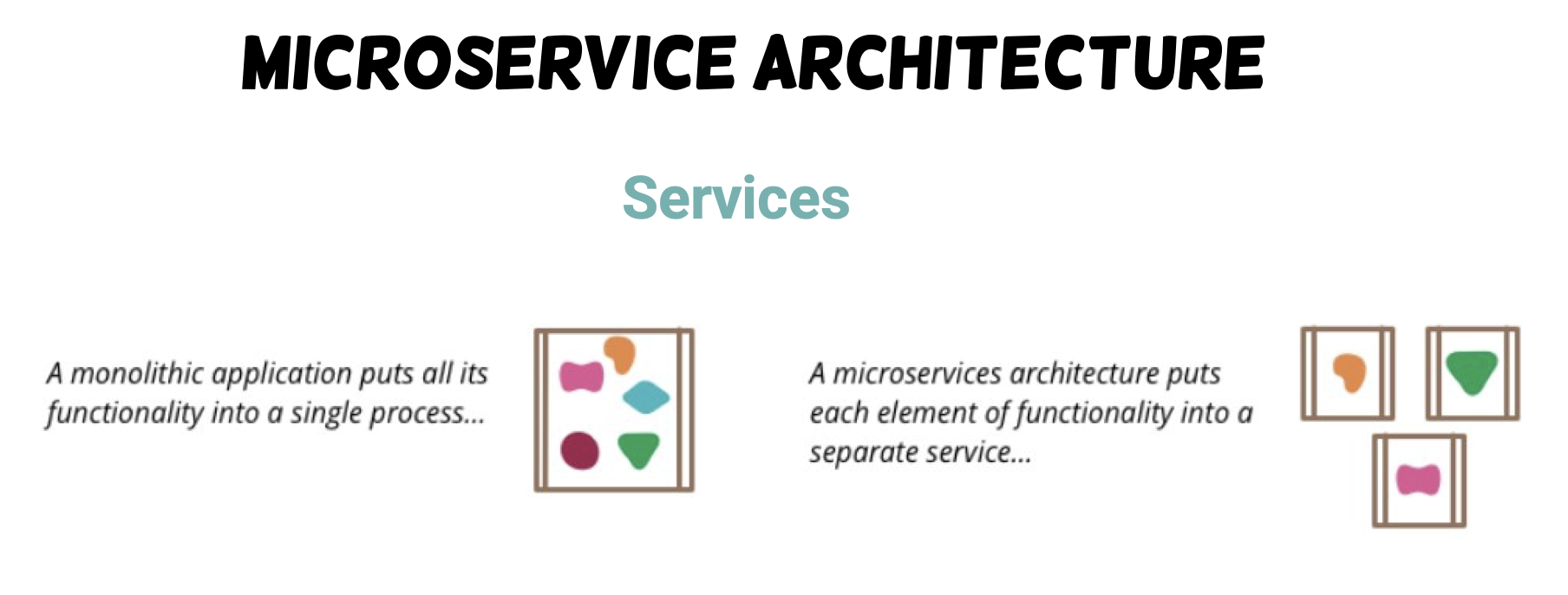
Monolithic Architecture [单体架构]
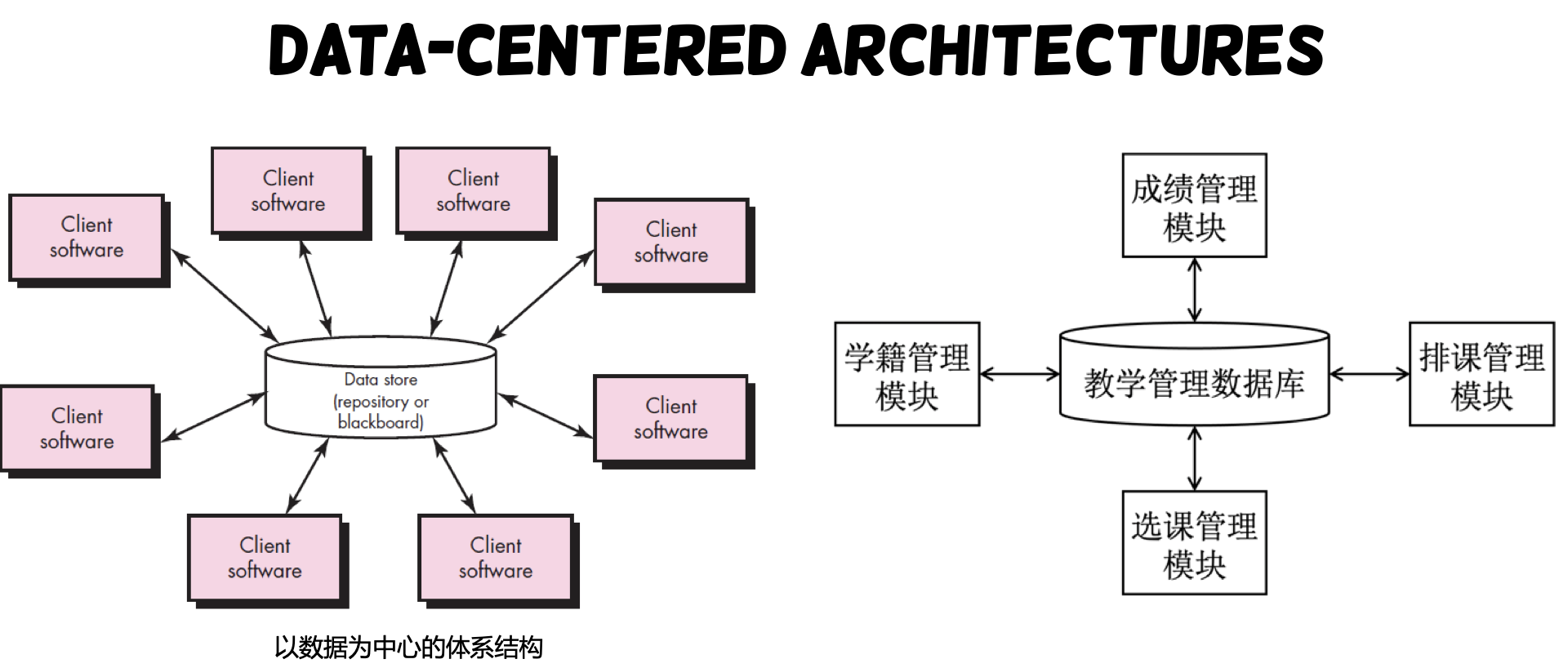
- A data store (e.g., a file or database) resides at the center of this architecture
- The data store is accessed frequently by other components that update, add, delete, or modify data within the store
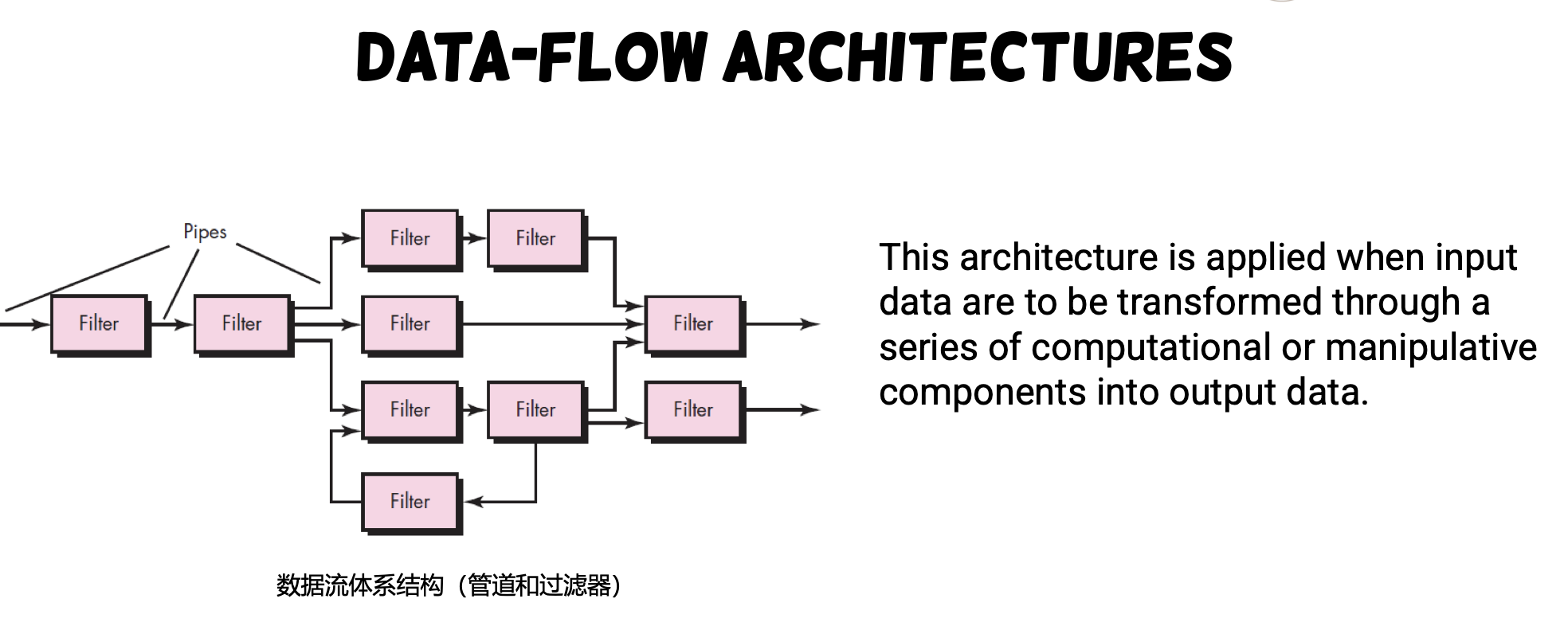
- A pipe-and-filter pattern has a set of components, called filters, connected by pipes that transmit data from one component to the next.
- Each filter works independently
- Expect certain form of input to produce output
- Suitable for automated data analysis and transmission systems
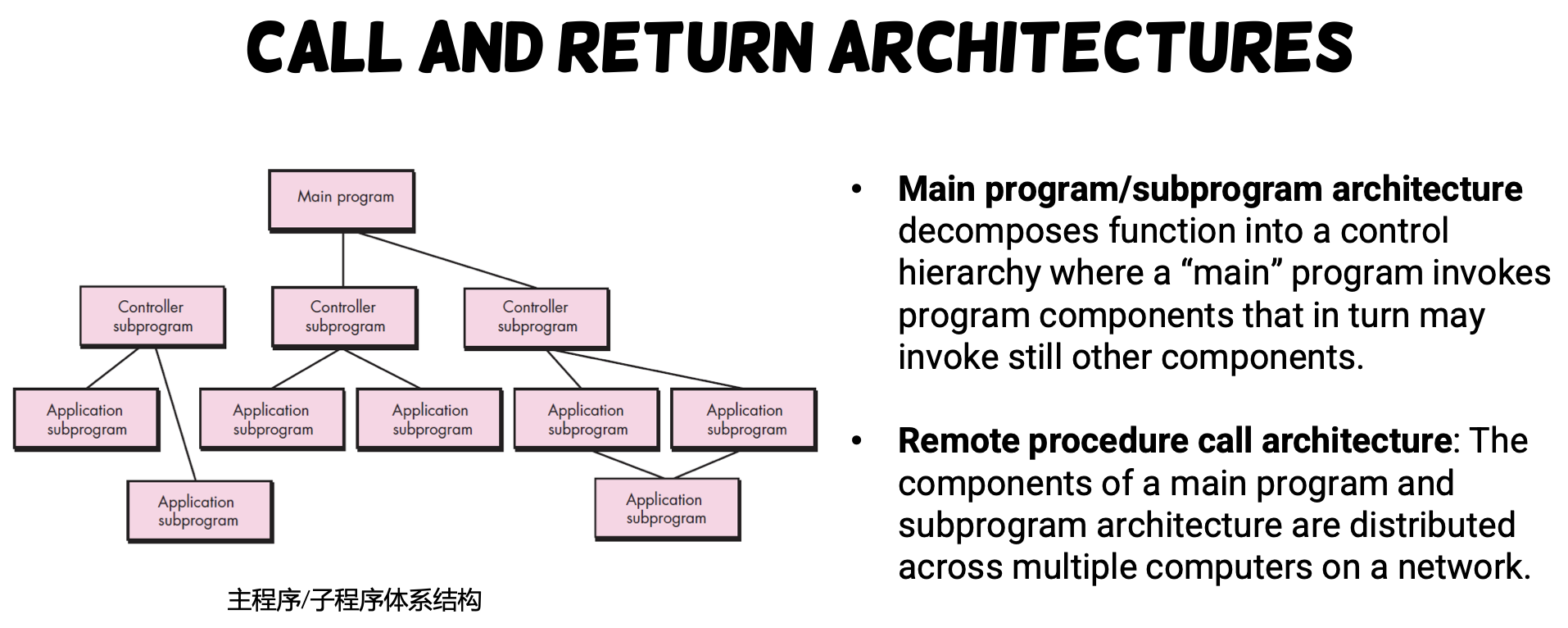
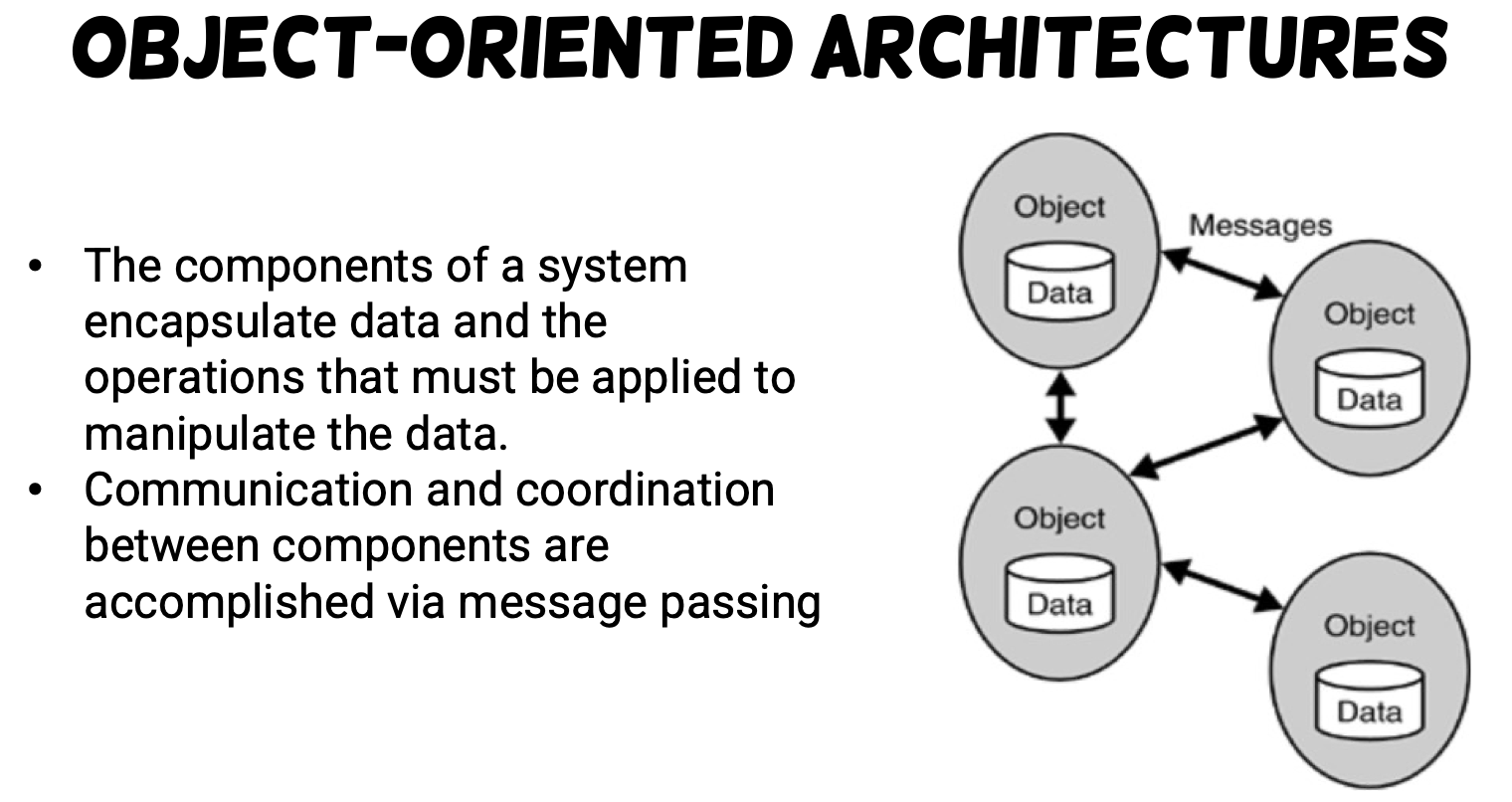
Monolithic Problems ?
- Bad for big project (management of code, service, etc.)
- Large overhead
- Slow down development lifecycle
Service-based, Distributed, DevOps
- Examples: IntelliJ, VSCode, Chrome, etc.
 |
 |
 |
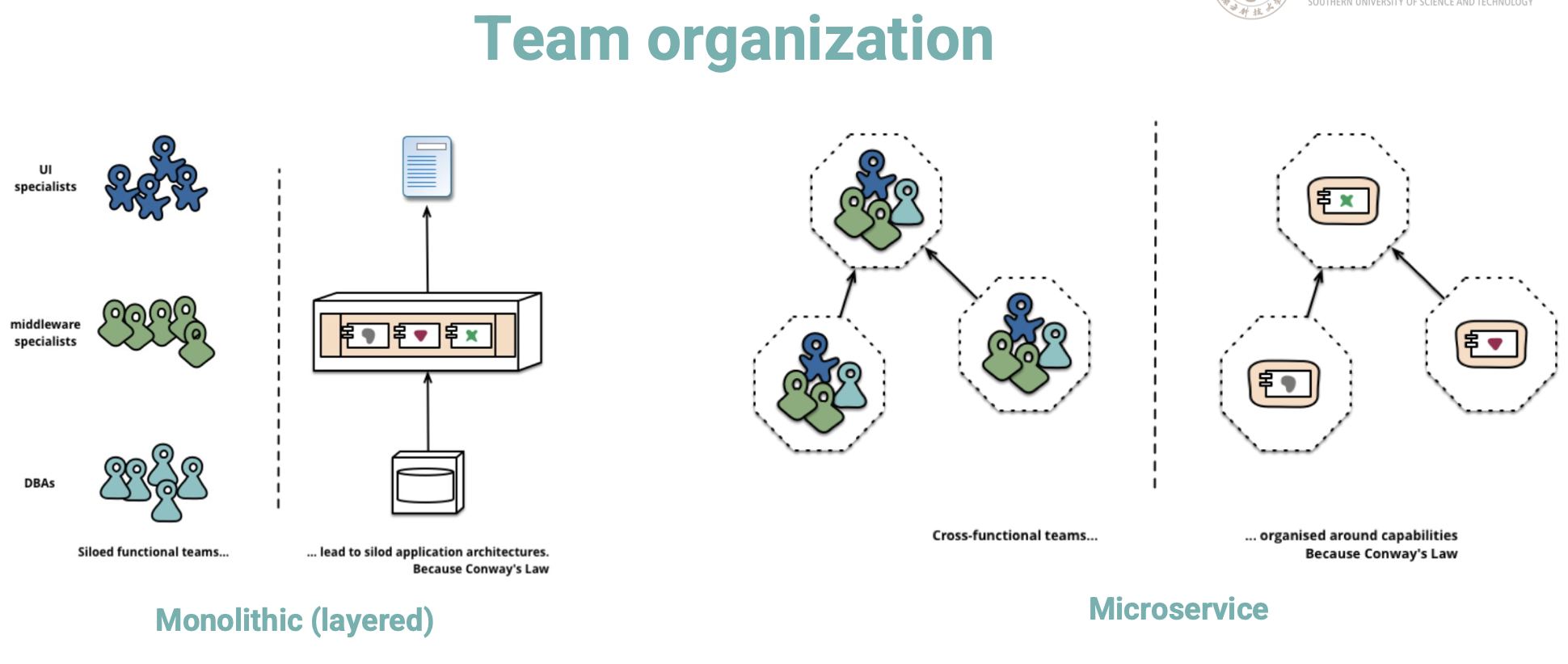 |
How do MicroService communicate?
- Synchronous
- The client expects a timely response from the service and might even block while it waits.
- E.g. RESTful API, gRPC
- Asynchronous
- The client doesn’t block, and the response, if any, isn’t necessarily sent immediately.
- E.g. The Messaging Model
Restful API
- Client-server: A client-server architecture made up of clients, servers, and resources (info like text, image, video)
- Resources could be accessed using URL
- Stateless: Resource requests should be made independently of one another
- Requests are made using HTTP protocol: GET, POST, PUT, DELETE
- Used by X (Twitter), Youtube, etc.
- REST API is best suited for applications with simple data sources where resources are well-defined.
- REST API is not suitable for fetching multiple resources in a single request
- Alternatives
- GraphQL: Meta(Facebook), Netflix Falcor
GRPC
- binary message-based protocol, facilitating efficient communication between distributed systems through Remote Procedure Calls(RPC).
- Support more operations (verbs) than REST
- Best suited for high-performance or data-heavy microservice architectures.
- Used by Netflix, Google, etc.
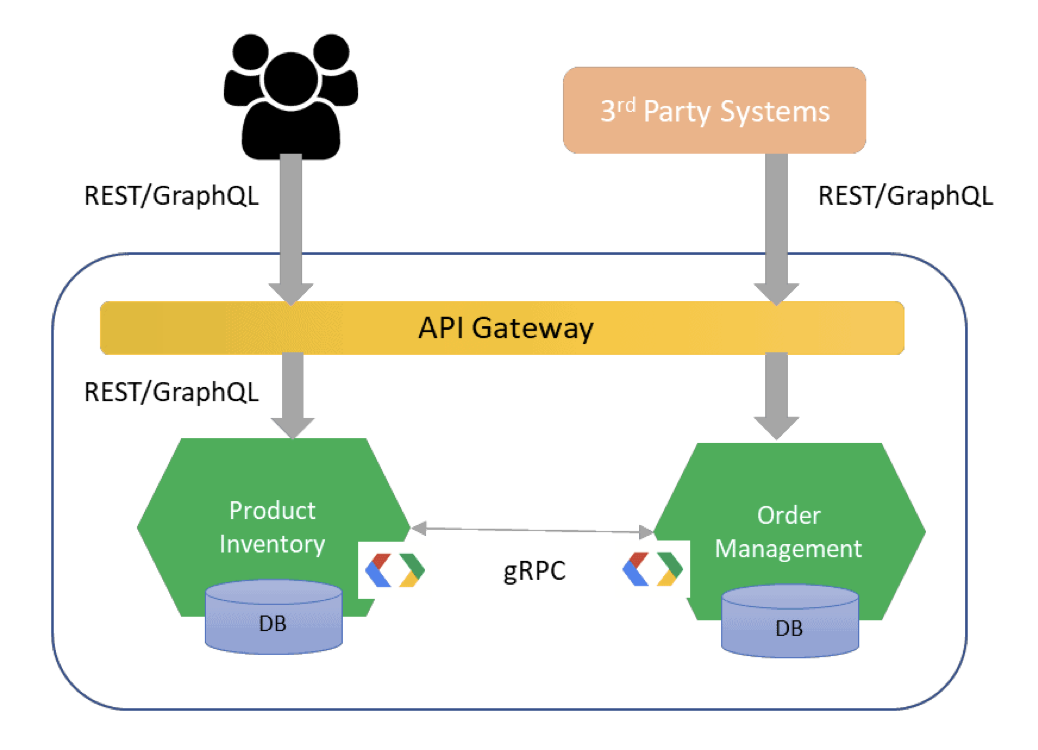
Messaging
- Data (messages) exchanged via Channels
- Use senders and receivers (instead of server/client)
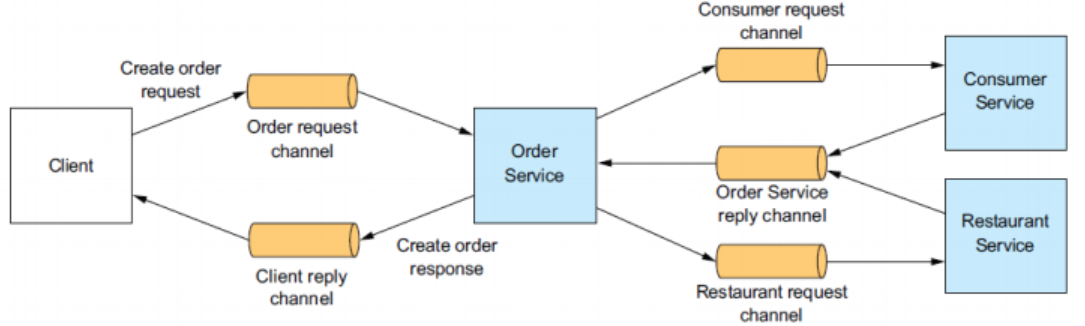
User interface design
- Visual Design
- Focuses on aesthetics, layout, color, typography, and visual hierarchy.
- Enhance usability and user experience.
- Interaction Design
- How users interact with UI elements (buttons, forms, navigation).
- Goal: Minimize friction and cognitive load.
- Principles
- Consistency >> e.g. 统一图标
- Clarity >> e.g. 警示操作用红色按钮
- Accessibility >> e.g. 菜单
- Feedback >> e.g. 密码输入返回
- Prototyping: an early sample or model of a user interface used to test concepts and gather feedback.
- Helps visualize design, test usability, and refine interactions before development.
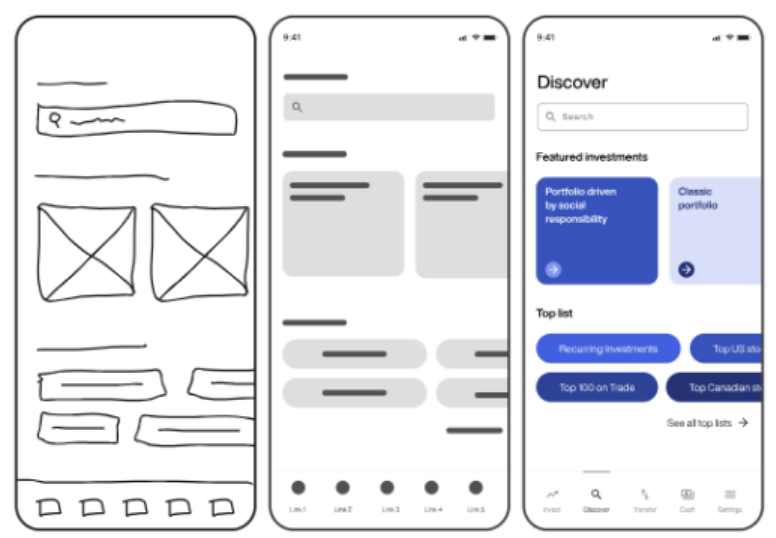
- Types(Stages)
- Low-Fidelity (Lo-Fi) Prototypes (低保真): hand-drawn or wireframes. Quick draft for design.
- Mid-Fidelity Prototypes (中保真): digital wireframes with basic interactions. Layout & interaction test.
- High-Fidelity (Hi-Fi) Prototypes (高保真): interactive and visually detailed. deployed product.
Lec 6. Build
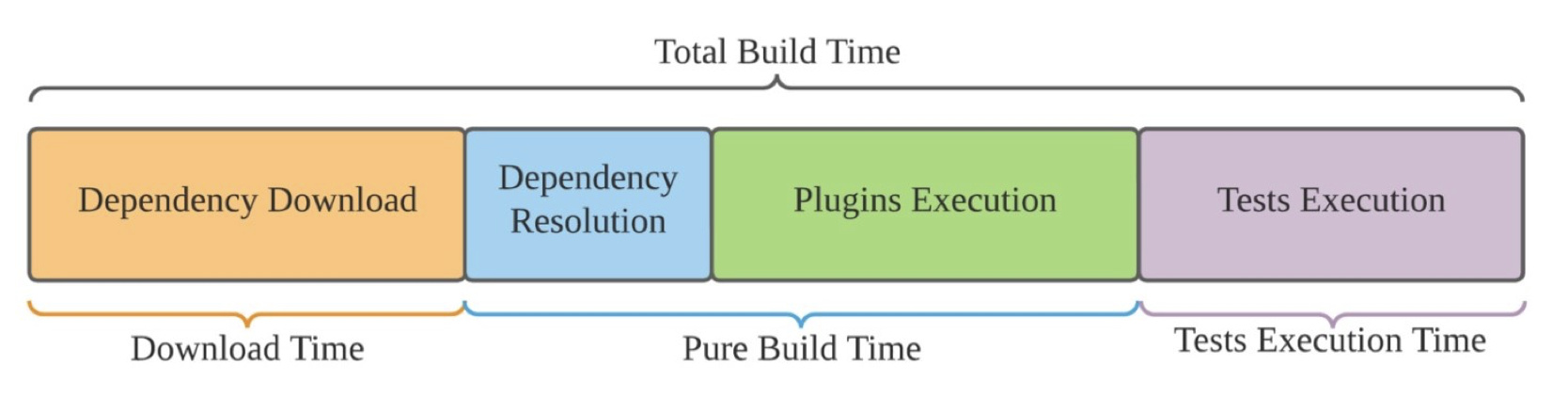
Build system overviews
- Goal: transforming the source code into executable binaries
- Building is the process of creating a complete, executable software by compiling and linking the software components, external libraries, configuration files, etc.
- Building involves assembling a large amount of info about the software and its operating environment.
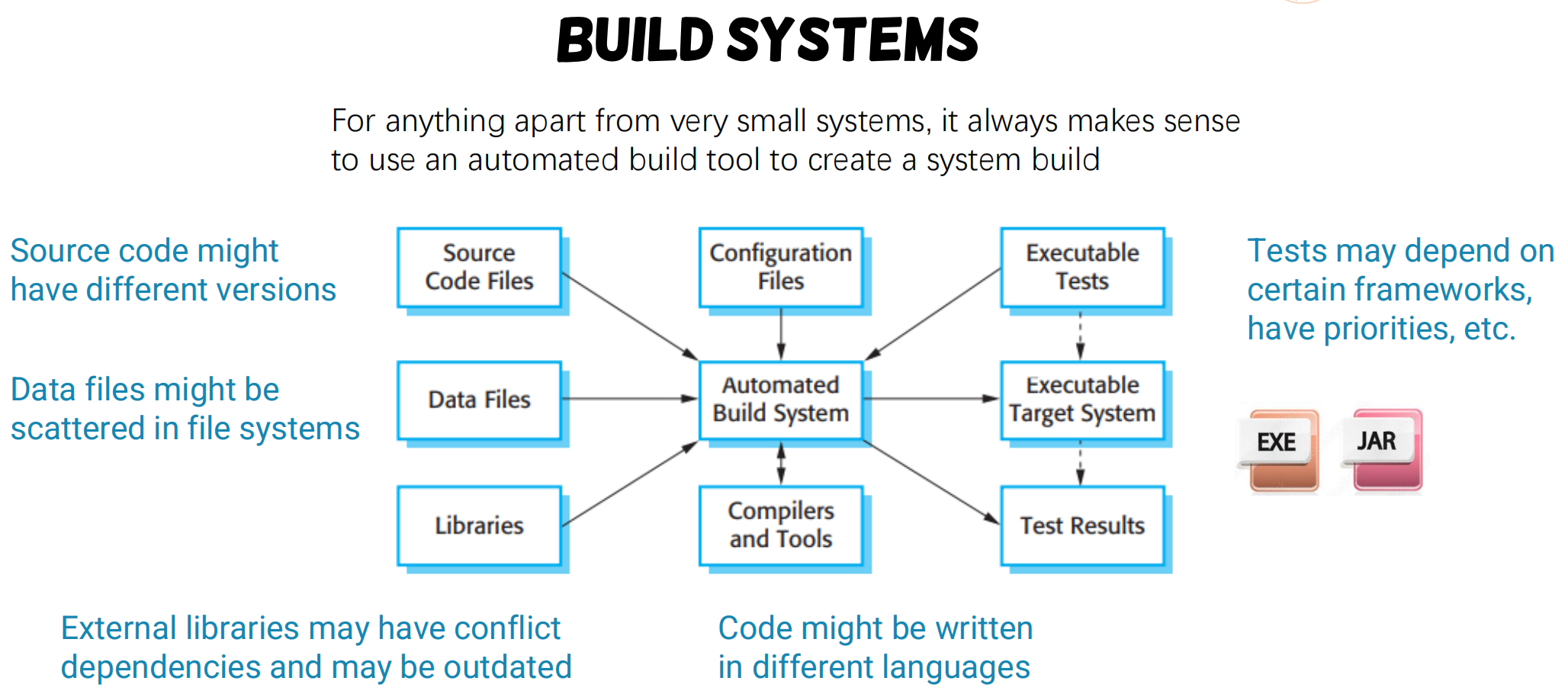
Types of build systems
Task-based Build Systems
- In a task-based build system, the fundamental unit of work is the task
- Each task is a script of some sort that can execute any sort of logics
- Tasks can specify other tasks as dependencies that must run before them
- Most major build systems (e.g., Ant, Maven, Gradle, Grunt, and Rake), are task based
- Most modern build systems require engineers to create build-files that describe how to perform the build (e.g.,
pom.xmlfor Maven)
Maven
- Build lifecycle: an ordered list of build phases. Maven has 3 lifecycles
- Build phase: a set of build tasks
- We can execute a build phase, which runs all phases prior to it and the phase itself
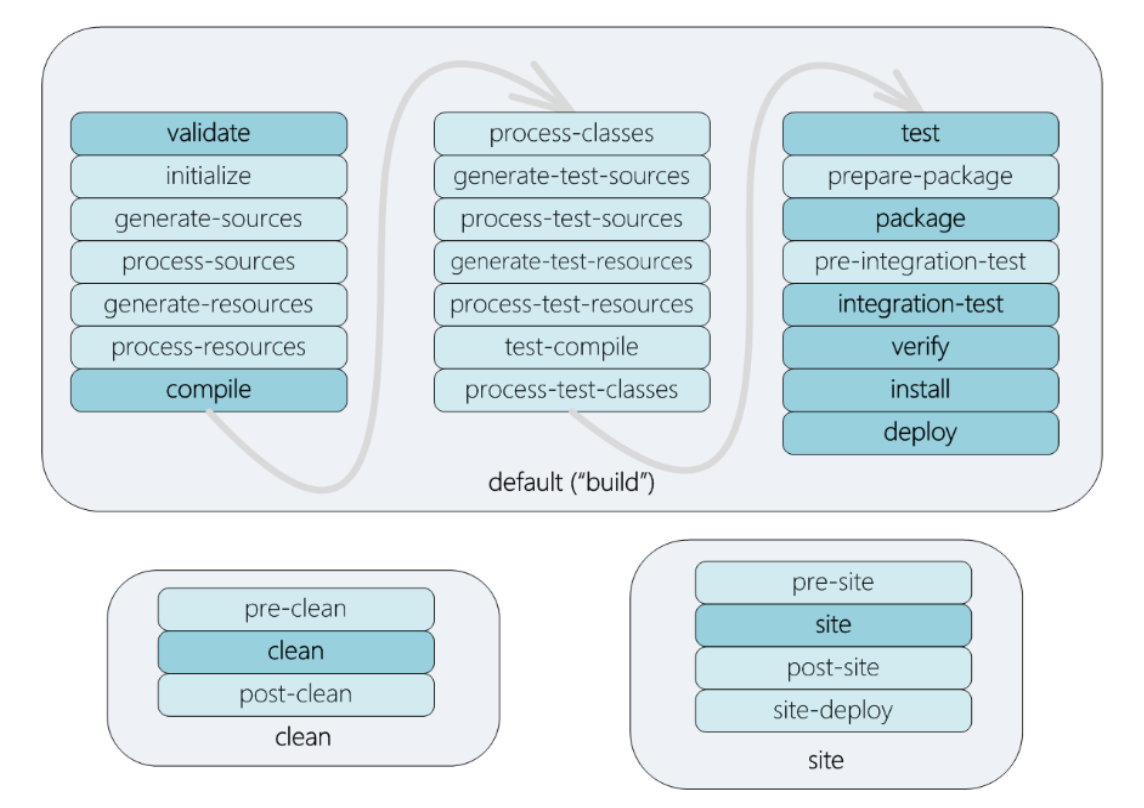
- Plugin: an artifact used for executing build tasks. A plugin provides one or more goals
- Goals: used to execute build tasks. Smallest step of maven builds
- Goals of plugins are attached to one or more phases
- We could also execute a plugin goal.
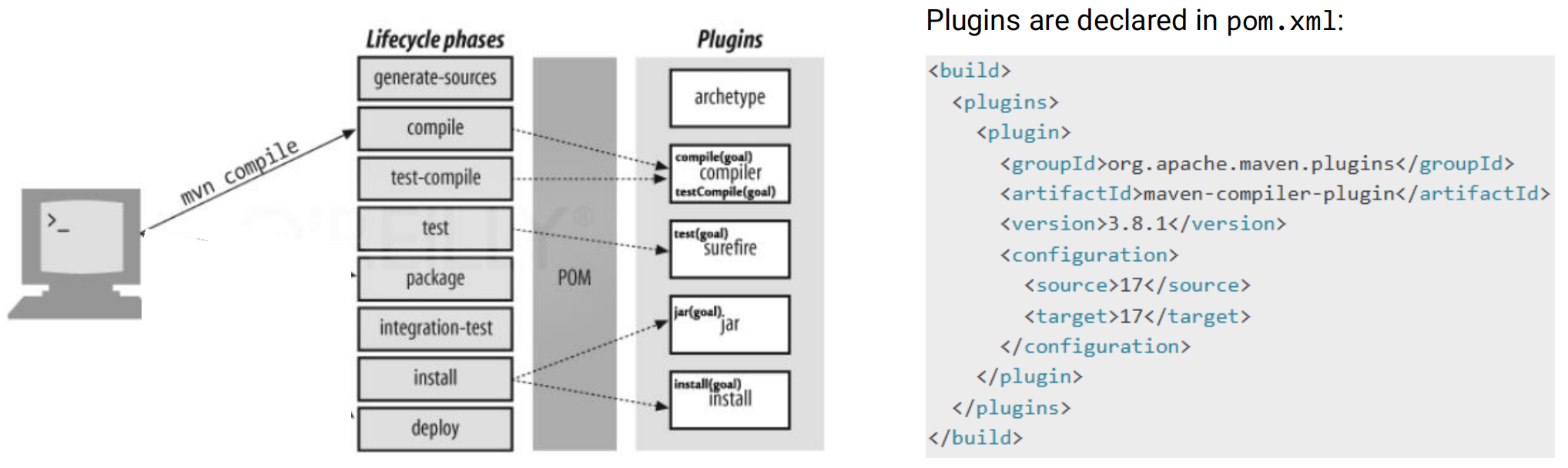
- The POM contains all necessary information about a project, as well as configurations of plugins to be used during the build process
- Drawbacks
- Difficulty maintaining & debugging build scripts
- give too much power to engineers (they define any script as a task)
- Difficulty performing incremental builds & parallelism
- hard to determine the change impact and side effects
- hard for incremental build and parallel build
- Difficulty maintaining & debugging build scripts
Artifact-based Build Systems
- Role of build systems: Build Artifact (e.g., executable binary, docs, etc.)
- Engineers define what to build, and BS define how.
Bazel
- Build-files: a declarative manifest describing
- Artifacts to build
- their dependencies
- configs
- Engineers: specify set of targets. (WHAT)
- Bazel: configuring, running, and scheduling the compilation steps (HOW)
- Targets: each correspond to an artifact
- Example
java binary: product binaries that can be directly executed.java library: produce libraries used by binaries or other libraries.
- Structure:
name: ref to target (like ID)srcs: source files to be compileddeps: targets that must be built before
- Build Process
- Parse all build-files to workspace to create graph of dependencies;
- Determine the transitive dependencies of, e.g.,
MyBinary;【依赖传递】 - Build dependencies in order;
- Build
MyBinaryto generate an executable file that links all dependencies built in (3).
- Benefits
- Parallelism: run step 3 in parallel
- Incremental Build: no side effects, rebuild only a few set of artifacts.
Build artifacts
Q1: How do we uniquely identify these artifacts?
A: Semantic Versioning
- Format:
{MAJOR}.{MINOR}.{PATCH}(e.g. 1.0.0, 2.4.72)MAJOR: a change to an existing API that can break existing usage (backward uncompatible)MINOR: purely added **functionality **(backward compatible)PATCH: non-API-impacting implementation details – low risk
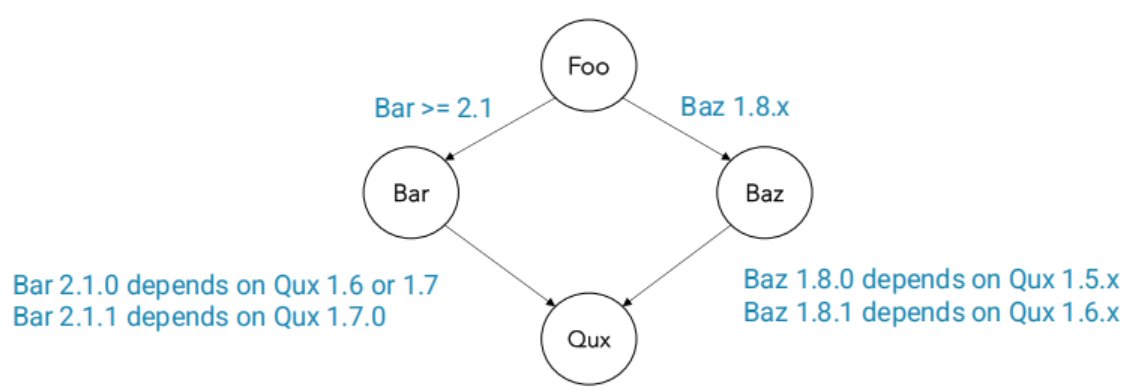
- E.g. As shown above, the build systems will find out the unique version of
Quxis1.6
Q2: Should we package dependencies into the final artifacts?
A:
- Bundle everything up
- pros: beneficial for end-user installed
- cons: time-consuming, dedicated distributor and hard to manage update
- Leave dependencies out
Q3: How do we manage the versions of these artifacts?
A: buildfile (e.g.
pom.xml) should be version controlled just like source code. Binary dependencies and artifacts are stored in other places (artifacts repo)
Summary
- As long as we have source code and the buildfile, we can always build the software
- That’s a crucial step for CI/CD (Lec 11.)
Managing dependencies
-
Internal vs. External Dependencies
- Int: depend on codebase owned by your project/team
- Ext: depend on that owned by $3^{\text{rd}}$ party providers.
-
Task vs Artifact Dependency
- Task: “I need to push the documentation before I mark a release as complete”
- Artifact: “I need to have the latest version of the compute vision library before I could build my code”
-
Dependency Scopes (when I need it)
- Compile-time
- Runtime
- Test
Dependency Problems
- Task A needs Task B. Owner of B update it, but owner of A doesn’t know until A failed.
1 | A -> B |
- As shown, if B decide not to depend on C, it causes Task A failed.
1 | A -> B -> C |
- Diamond Dependency Issues: unexpected resuls
1 | A -> B -> D |
- Circular Dependency
Lec 7. Quality Control
Where we’re in?
Quality control: code quality
What should be considered in code quality?
User-Oriented
- Correctness (正确性)
- Reliability (可靠性)
- Security (安全性)
- Efficiency (高效性)
Developer-Oriented
- Portability (可移植性)
- Readability (可读性)
- Maintainability (可维护性)
Evaluating Code Quality
Metrics
Line of Code
- relatively measure readability and maintainability
- a metric for developer
- Problems:
- needs to be normalized to be meaningful and comparable
- is language related (不同语言实现的代码量不同)
Cyclomatic Complexity
- Cyclomatic complexity (圈复杂度) is a software metric used to indicate the logic complexity of a program.
- computed using the control-flow graph (控制流图) of the program
- Core idea: complexity of code depends on the number of decisions in the code.(
if,while,for) - control-flow graph:
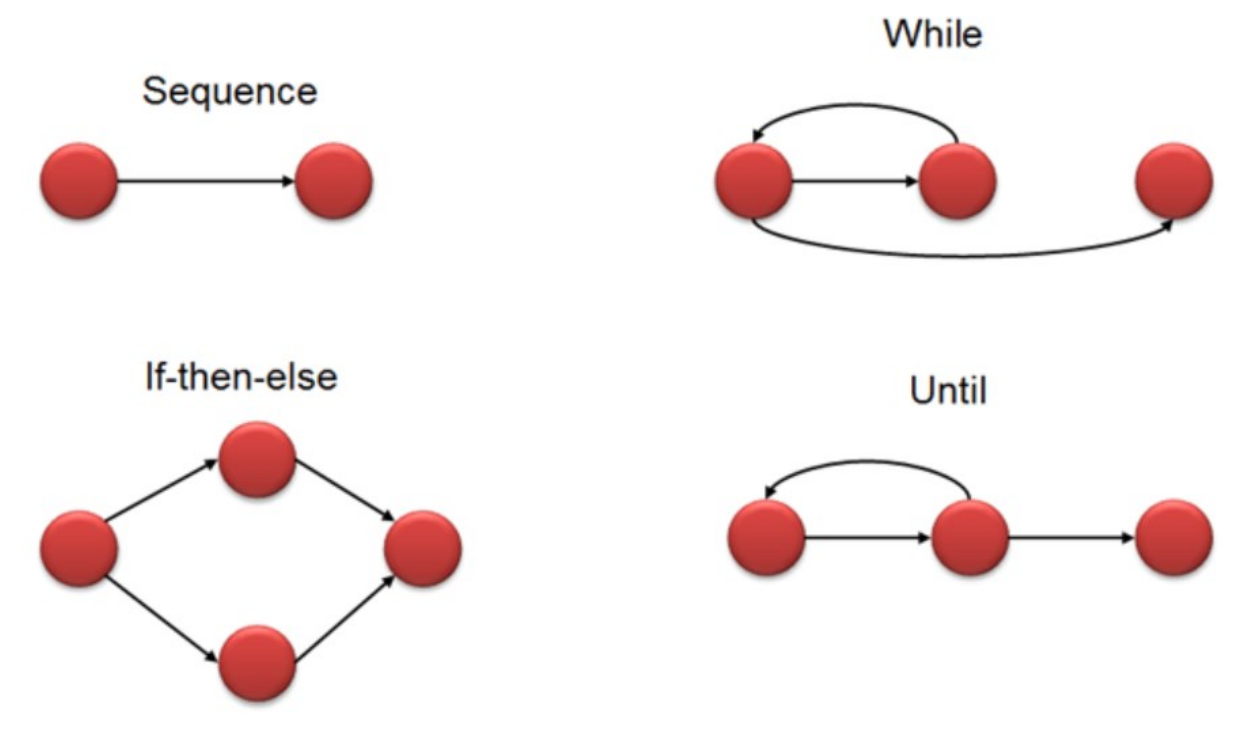
- Approach 1: $V(G)=P+1$
- $P$ : Number of branch nodes (e.g., if, for, while, case)
- Approach 2: $V(G)=E-N+2$
- $E$ : number of edges; $N$ : number of nodes
OO Metrics (ckjm – Chidamber and Kemerer Java Metrics)
- Weighted Methods per Class (WMC)
- indicate the development and maintenance effort for the class
- Depth of Inheritance Tree (DIT)
- the deeper a class is, the more methods it inherits, the harder to predict its behavior
- Number of Children (NOC)
- indicates the number of immediate subclasses
- Coupling (耦) between Object Classes (CBO)
- Coupling: Dependencies between modules, which is bad (cohesion is that within modules, good)
- CBO represents the number of classes coupled to a given class. (CBO=1 - 4 is good)
- Lack of Cohesion in Methods (LCOM)
- counts the sets of methods in a class that are not related through the sharing of some of the class’s fields.
- $LCOM=P-Q$ where
- $Q$: In some pairs, both methods access at least one common field of the class
- $P$: In other pairs, the two methods do not share any common field accesses
Linters
- A linter (静态语法检查器) is a tool that analyzes source code for style, syntax, and potential errors that can lead to bugs and vulnerabilities
- Purpose: Static analysis for syntax, style, and errors.
- Tools:
- ESLint (JavaScript/TypeScript)
- Pylint (Python)
- SpotBugs (Java)
- Integration: Often part of build pipelines.
Code Review
-
Targets (code types to be reviewed):
- Modifications to existing code
- Entirely new code
- Automatically generated code
-
Goals:
- Ensure design quality, functionality, complexity and adherence to style guides.
- Ensure well-designed unit tests
- Ensure clear comments, appropriate document and clear names.
-
Tools: GitHub Copilot (AI-assisted review), Crucible, Gerrit.
AI-Generated Code & Quality
- Challenges:
- Lower code quality due to over-reliance on AI tools.
- Survey on metrics that should be used for AI coding: code quality (36%), production incidents (33%).
- Example: AI tools may introduce subtle bugs (e.g., variable name typos).
Lec 8. Testing
Where we’re in?
Quality control: testing
Core Testing Concepts
3 Stages of Testing
- Basic testing: Constraint based, needs based
- Developer-driven testing: make developers responsible for their codes.
- Automated testing: good for large-scale testing, another important component of CI/CD
Test Case vs. Test Suite
- Test Case:
- Validates a specific feature (e.g., valid login)
- Includes prerequisites, steps, and expected outcomes.
- Test Suite:
- Collection of test cases grouped by functionality (e.g., “Checkout Process” suite).
Test Input vs. Test Oracle
- Test Input: Data fed into the system (e.g., username/password).
- Test Oracle: Source of correct expected outputs (e.g., specifications, expert judgment).
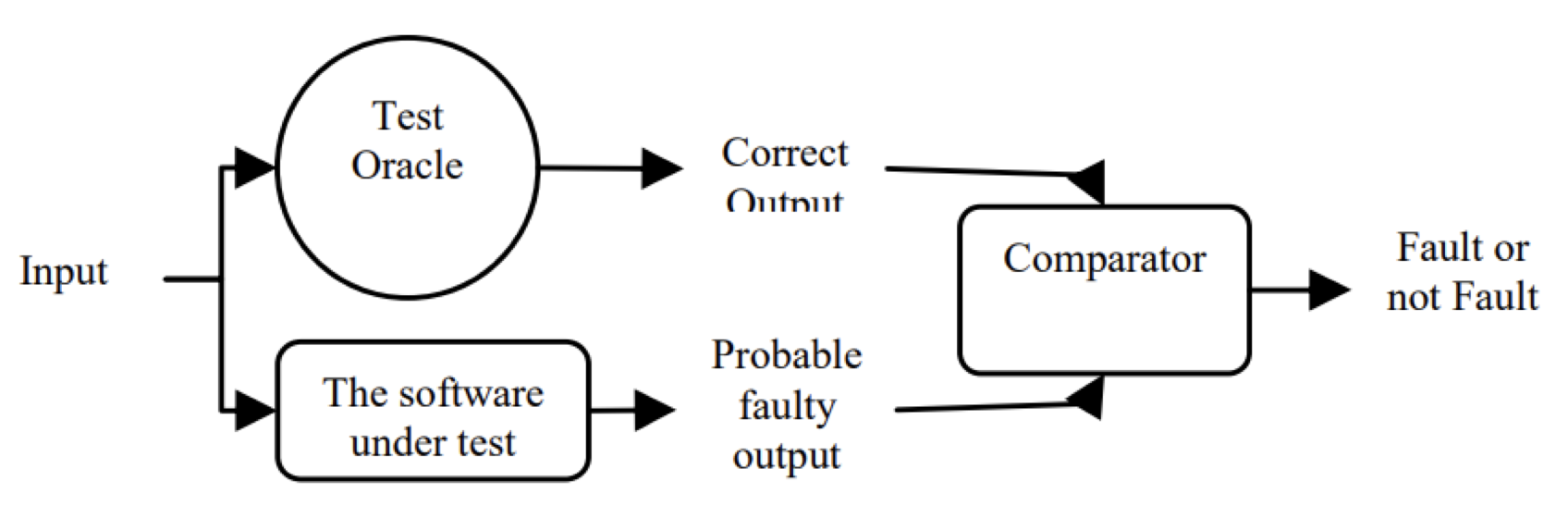
Testing Quadrants
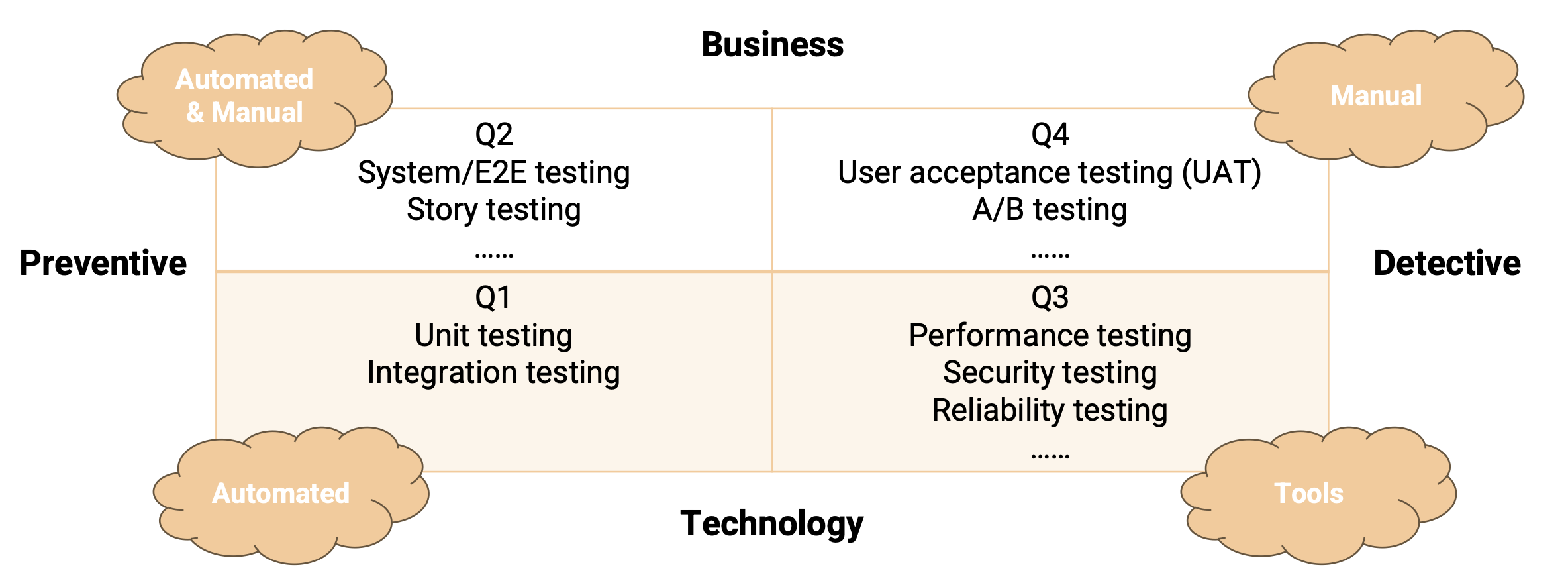
Testing Levels & Types (Q1 and Q2)
Unit Testing
- Scope: Smallest code units (methods/classes)
- Focus:
- Local data structures
- Boundary conditions (e.g., input limits)
- Error handling paths
Integration Testing
- Goal: Verify interactions between modules.
- Example:
| Test ID | Objective | Expected Result |
|---|---|---|
| 1 | Login → Mailbox interface | Redirect to Mailbox |
| 2 | Mailbox → Delete Email | Email moved to Trash |
System Testing
- Purpose: Validate end-to-end functionality to fulfill business specifications. (whether it’s ready for deployment)
- Environment: conducted in
prodenvironment (仿真)
Comparison
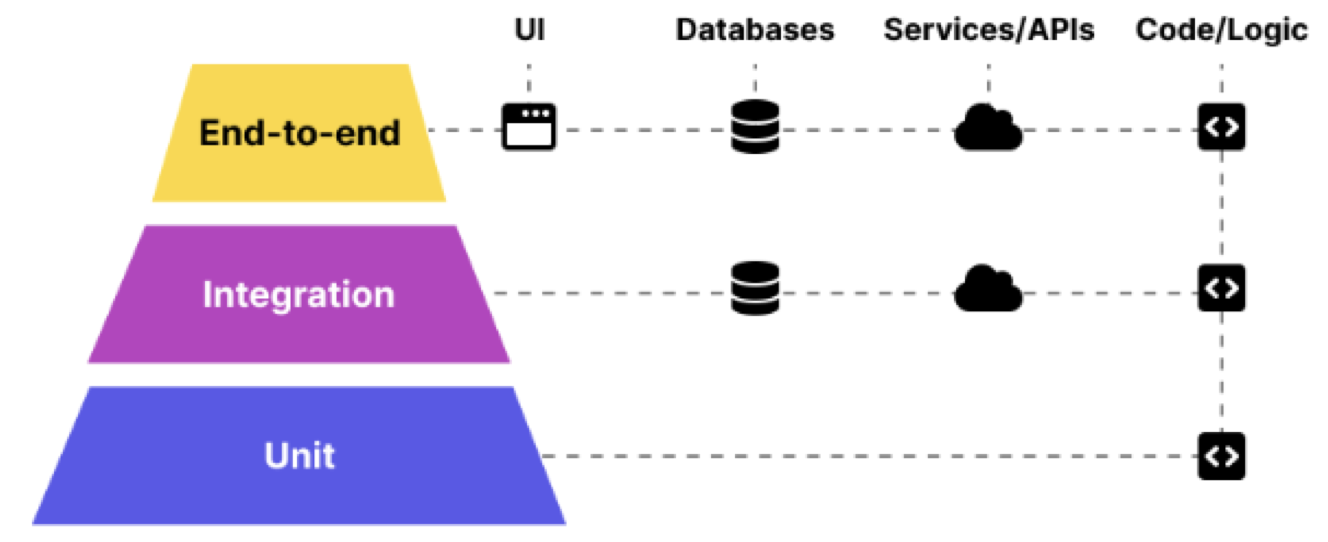
Test Size
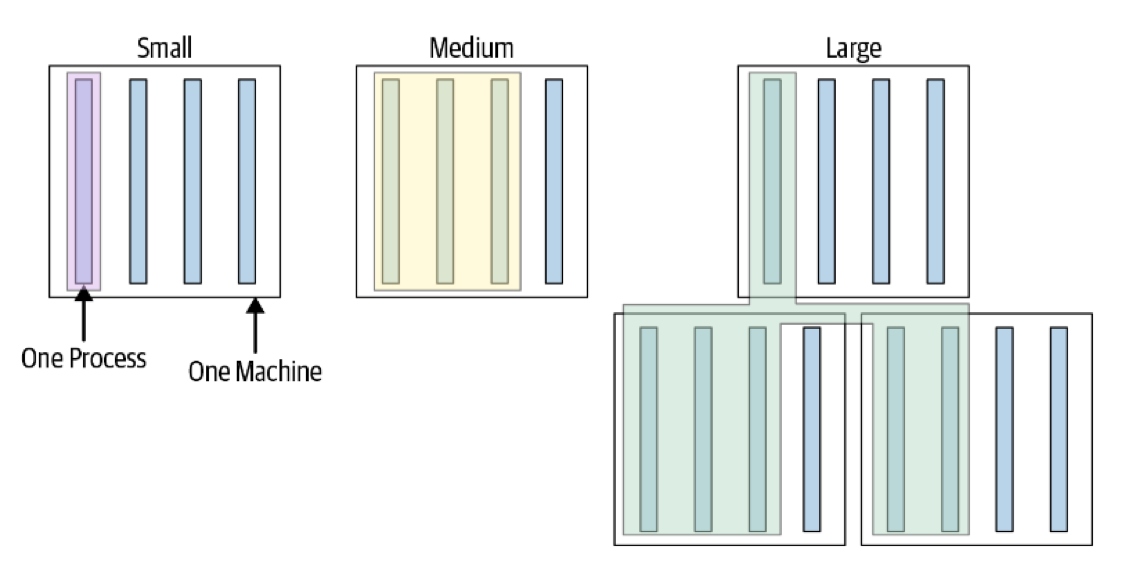
- Small tests: single thread/process, no blocking calls —— fast, effective and reliable
- Medium tests: run on single machine, multiple processes, enable testing integration of multiple components
- Large tests: run on multiple machines over network, more about validating configurations.
Testing Levels & Types (Q3 and Q4)
Performance Testing
- Types:
- Load Testing: Simulate expected user traffic.
- Stress Testing: Exceed normal load capacity.
- Endurance Testing: Prolonged load simulation.
- Spike Testing: Sudden traffic surges.
- Volumn Testing: Test capacity
User Acceptance Testing (UAT)
- Performed By: End-users/business stakeholders.
- Focus: Real-world usability and requirements compliance.
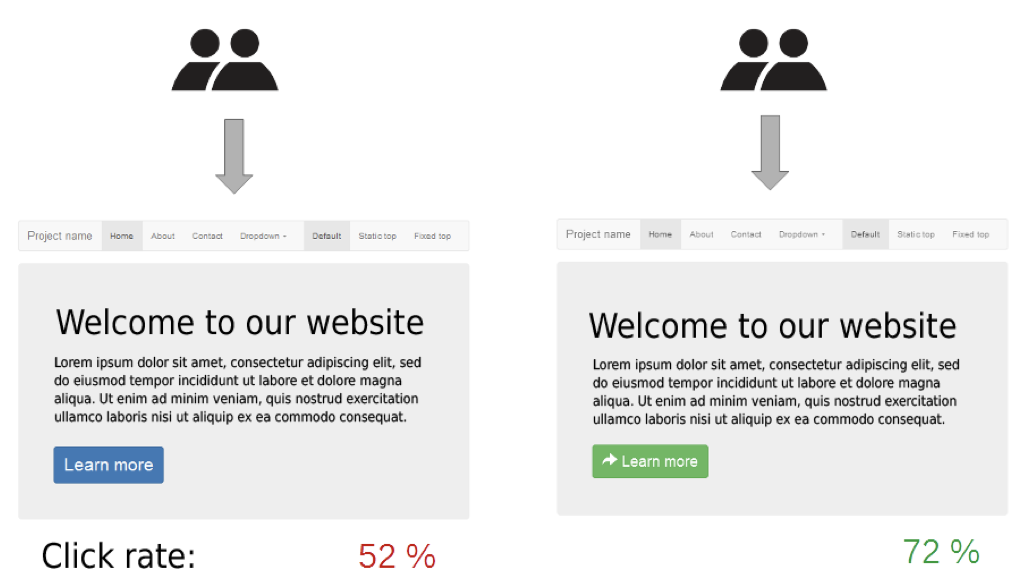
A/B Testing
- Use Case: Compare UI/UX variants (e.g., button colors).
- Outcome: Data-driven design decisions (e.g., 72% click rate for variant B).
Testing Pyramid & Size
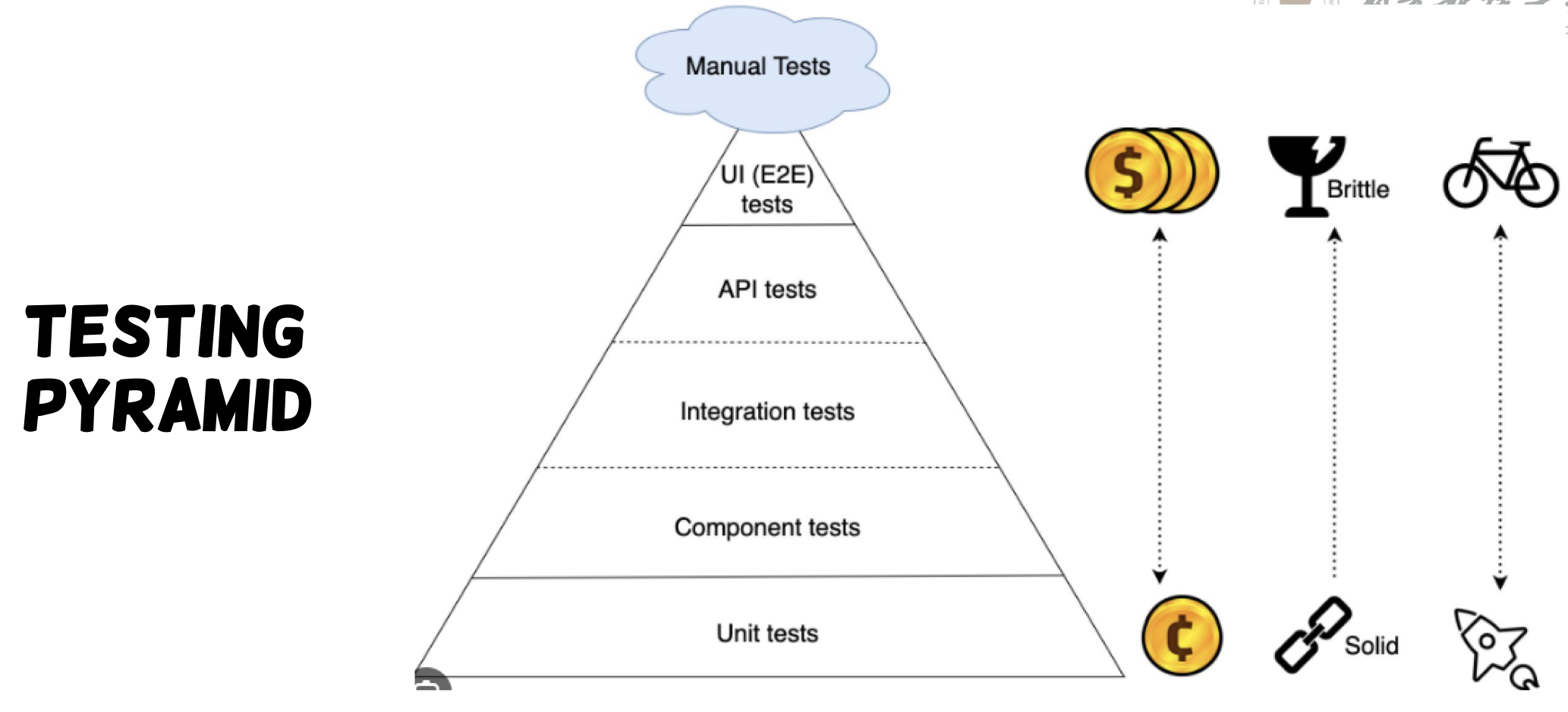
Testing Pyramid
- Foundation: Unit tests (80% coverage)
- Middle: Integration tests (15%)
- Top: E2E/UI tests (5%)
Testing Techniques
Black-box & White-box Testing
| Black-box | White-box | |
|---|---|---|
| Basis | Software specifications (no code visibility) Internal program structure is unknown Cover as much specified behaviors as possible |
Source code structure Internal program structure is known Cover as much coded behaviors as possible |
| Pros | simplicity, realistic results | comprehensive testing, early bug detection |
| Cons | Limited coverage (misses edge cases) | Requires technical expertise, expensive, limited real-world simulation. |
Coverage Metrics (for white-box)
- Code coverage (代码覆盖率) is a metric that shows how much of an application’s code has tests checking its functionality
- Statement Coverage:
$$
\text{Statement Coverage}=\frac{\text{Num of executed statements}}{\text{Total num of statement}} * 100%
$$
- e.g.
a=1, b=2for the following code, statement coverage is $5/7 \approx 71%$
1 | sum(int a, int b) { |
If test case #1:
a=1, b=2; test case #2:a=-2, b=-4, then SC of test suite(tc1 + tc2) = 100%Is that what we want ?
- Branch Coverage $=(\text{num of executed branches} / \text{num of total branches})*100%$
- for the same example, we only got BC = 75% (then we check out a bug)

What if the following condition happens?

- Condition Coverage $=(\text{num of conditions that are both T and F}/\text{num of total conditions})* 100%$
Test Data Selection (for Black-box testing)
- Exhausted testing: test all possible conditions (absolutely impractical)
- Random Testing: good in normal case (what if failure are dense in some subdomains?)
- Partition Testing: divides input data into equivalent data classes (等价类).
- Random choice in each partitions
- Equivalence Partition Hypothesis: if one condition/value in a partition passes, then all others will also pass, vice versa.
- Boundary Values: Assume that errors tend to occur at boundary of a subdomain. Choose boundaries data between partitions.
Lec 9. Testing (2)
Maintainable Unit Tests
Ultimate Goal: Unchanging Tests
- Ideal Scenario: Tests remain unchanged unless system requirements change.
- Characteristics:
- Tests “just work” after being written.
- Failures indicate real bugs with clear causes.
- Impact of Changes:
- Refactoring: Should not affect existing tests.
- New Features/Bug Fixes: Require new tests but leave existing ones intact.
- Only changes to system behavior necessitate test updates.
Best Practices for Maintainable Tests
1. Test via Public APIs
- Why? Public APIs change less frequently than internal implementations.
- Benefits:
- Tests mimic real user interactions.
- Less brittle[脆弱] to internal refactoring.
- Serve as documentation/examples for users.
2. Test Behaviors, Not Methods
- Problem with Method-Driven Tests:
- Tests grow complex as methods evolve.
- E.g. A single test for
displayTransactionResults()becomes convoluted when new behavior (e.g., low balance warning) is added.
- Solution: Split tests by behaviors:
- One test checks if the item name is displayed.
- Another test verifies low balance warnings.
Integration Tests: Test Doubles
Why Use Test Doubles?
- Imagine test suite run with external server and stores responses in database (issues?):
- Slow execution (e.g., external APIs/databases).
- Flakiness (e.g., network issues).
- Types of Test Doubles:
| Type | Purpose | Example |
|---|---|---|
| Stub | Returns predefined data to SUT (system under test) Respond to specific inputs with specific outputs Used when we don’t want to involve objects that have undesirable side effects |
A UserService stub returns a fixed user. |
| Fake | Simplified/in-memory implementation Pre-written implementation of the object that are supposed to represent Idea: removing unnecessary/heavy dependencies(e.g. database) |
A fake DatabaseService uses a HashMap instead of disk storage. |
| Mock | similar to Stub, add behavior verification Purpose: assert how SUT interacted with dependency Used when we don’t want to invoke production code or when there is no easy way to verify that intended code was executed |
A mock CreditCardService confirms chargeCreditCard() was invoked. |
- Mocking Frameworks:
- Tools like Mockito simplify creating mocks. For example, a mock
CreditCardServiceis configured to returnfalsefor charge attempts, allowing tests to validate error handling.
- Tools like Mockito simplify creating mocks. For example, a mock
UI Testing
Overview
- Goal: Validate UI functionality and appearance as an end user would.
- Key Aspects:
- Consistency: Fonts, colors, layout.
- Spelling/Typography: Readability, contrast.
- Interactive Elements: Buttons, forms, etc. work as intended
- Functional validation: Expected outputs for specific inputs
- Adaptability: Responsiveness across devices/browsers.
Automation with Tools
- Example: Selenium automates browser interactions
- Tests validate scenarios like adding items to a cart or enforcing input constraints (e.g., blocking negative numbers).
Evaluating Test Quality
Test Metrics
- Coverage:
- Requirements Coverage $=\frac{\text{Covered Requirements}}{\text{Total Requirements}} \times 100%$
- Code Coverage: Statement/branch coverage.
- Test tracking: Passed percentage / Failed percentage
- Defect Tracking:
- Metrics include Accepted/Rejected Defects, Critical Defects, and Deferred (延迟的) Defects.
Mutation Testing
- Process:
- Introduce small code changes (mutation operators), e.g., altering a loop condition (
<to>). - Run tests; mutants are “killed” if any tests fail.
- Calculate Mutation Score: $\text{Mutation Score} = \frac{\text{Killed Mutants}}{\text{Total Mutants}} \times 100%$
- Introduce small code changes (mutation operators), e.g., altering a loop condition (
- Purpose: Higher mutation score increases the confidence of using the original test cases
Fuzzing (模糊测试)
- Goal: Discover crashes/memory leaks via invalid inputs (e.g.,
null, SQL injection strings). - Types:
- Generation-based: Create inputs from scratch.
- Mutation-based: Modify existing inputs (e.g., inserting emojis or binary data).
- Coverage-guided Fuzzers: focus on finding inputs that cause new code coverage to explore edge cases that may crash the program.
Lec 10. Documentation
This piece is “missing” from DevOps, actually lies before release.
Types of Software Documentation
External Documentation
- End-user Documentation:
- Provides instructions for installation, usage, and troubleshooting.
- E.g. User manuals, quick start guides, FAQs.
- Just-in-time Documentation:
- Offers context-specific support when users need it.
- Examples: Tooltips, in-app help, contextual tutorials.
Internal Documentation
- Administrative Documentation:
- High-level guidelines for teams (e.g. project roadmaps, status reports).
- Developer Documentation:
- Guides developers in building/maintaining the software.
- Includes:
- Requirements docs: Functional and non-functional specifications.
- Architecture/design docs: System structure and design decisions.
- API docs: Usage instructions for interfaces.
- Code comments: Inline explanations of code logic.
- Readme/Release notes: Setup and usage instructions.
Best Practices for Documentation
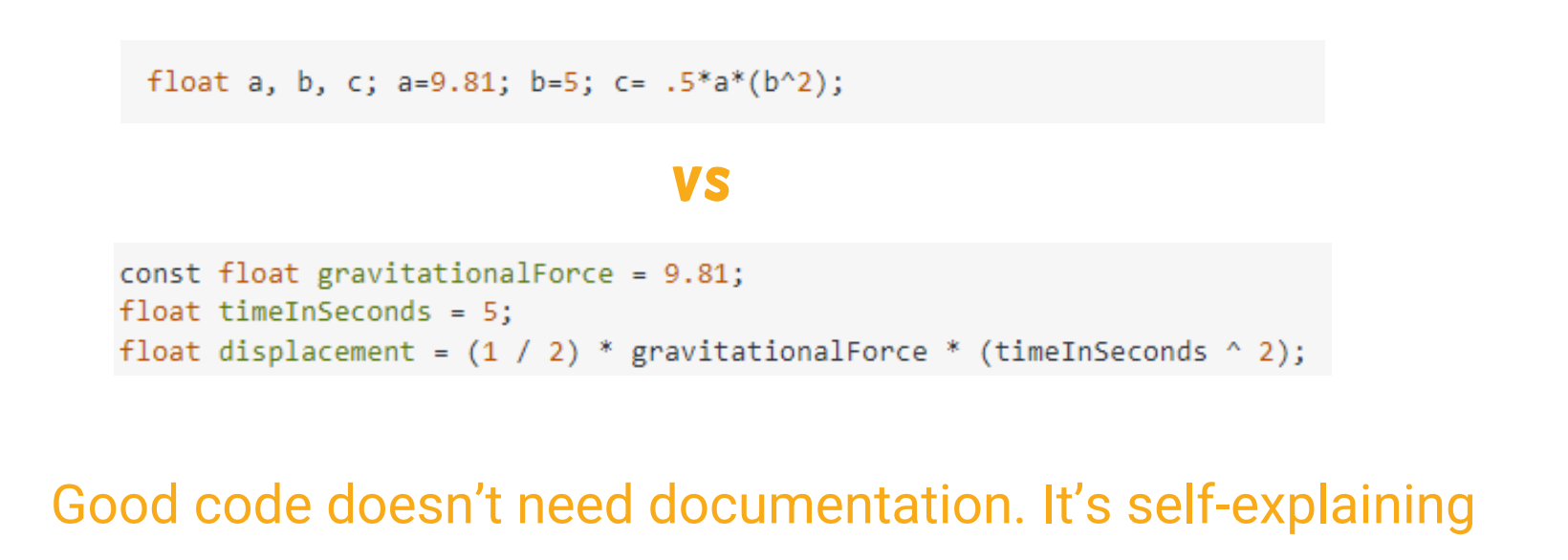
1. Self-Documenting Code
- Goal: Make code readable without external explanations.
- Techniques:
- Meaningful names: Use
gravitationalForceinstead ofg. - Structured logic: Avoid “magic numbers” (e.g., replace
if (port < 1024)withif (port <= HIGHEST_PRIVILEGED_PORT)). - Modular design: Break code into small, reusable functions.
- Meaningful names: Use
2. Effective Code Comments
- When to Comment:
- Explain WHY (rationales), not WHAT (implementations).
- Highlight technical debt (e.g.,
// TODO: Refactor this hack). - Warn about edge cases (e.g.,
// WARNING: This test takes 15 minutes).
- Examples:
- Bad:
// Multiply a and b - Good:
// Use Newton’s equation to calculate displacement
- Bad:
3. Javadoc for API Documentation
- Syntax:
- Use
/** ... */for class/method-level comments. - Include tags like
@param,@return,@throws.
- Use
- Call for generation
1 | javadoc -d C:\home\html -sourcepath C:\home\src java.my.package |
- Example:
- Class-level: Describes the purpose of a
SuperHeroclass. - Method-level: Explains inputs, outputs, and exceptions for
get(int index).
- Class-level: Describes the purpose of a
Documentation Generators
- Sphinx: Generates HTML/PDF docs
- Swagger: Documents REST APIs with interactive UIs.
- GitBook: Collaborative platform for technical docs.
Less Recognized Documentation
Tests as Documentation
- Demonstrate API usage (e.g.,
shouldTransferFunds()). - Validate edge cases (e.g.,
shouldThrowExceptionIfStackIsEmpty()).
Git Commit Messages
- Explain why a change was made.
- Reference issues (e.g.,
Closes #20: Fix null pointer exception).
Documentation as Code
Case study: Google
Challenges
- Poor Documentation Culture:
- Docs were outdated, hard to find, or nonexistent.
- Engineers lacked incentives to write/maintain docs.
Solution: “Docs as Code”
-
Integration with Codebase:
- use
g3docfor rendering - Store docs in Markdown files alongside source code.
- Use version control (e.g., Git) for tracking changes.
- use
-
Benefits:
- Collaboration: Code reviews, diffs, and blame tracking.
- Accessibility: Rendered as HTML for easy browsing.
- Consistency: Docs stay updated with code changes.
Outcomes
- Scalability: Over 10,000 projects adopted
g3doc. - Cultural Shift: Documentation became a core engineering practice.
Lec 11. Continuous Integration and Continuous Deployment (CI/CD)
Where we’re in?
Release: automate commit + build + test
Outline
- History of CI/CD
- Continuous Integration (CI)
- CI Process
- CI Servers
- CI/CD Pipeline
- Deployment Strategies
- Branching Strategies
- Case Study: CI/CD at Meta
History of CI/CD
1980s at Microsoft
- Context: In the 1980s, Microsoft’s products grew too complex for individual developers to manage alone.
- Solution: Introduced the concept of “daily build” or “nightly build.”
- Developers synchronized their work daily and stabilized the product incrementally throughout the project, rather than waiting until the end.
- The latest version was built every day, ensuring it remained in a runnable state.
- Reference: ACM Article
Insert Image: Slide 4 - “HISTORY”
1990s at Chrysler (C3 Project)
- Context: The Chrysler Comprehensive Compensation System (C3 Project) aimed to support 90,000 employees but faced significant difficulties and delays.
- Challenge: In 1996, Kent Beck and his team found that integrating and running the project code took one to two weeks, slowing development.
- Solution: Increased integration frequency.
- Resulted in significantly reduced integration time.
- Enabled earlier detection and resolution of software issues.
- Impact: This practice laid groundwork for modern CI principles.
Insert Image: Slide 5 - “HISTOR”
Continuous Integration (CI)
- Definition: Developers commit changes in small increments (at least daily, often multiple times a day).
- Process:
- Each change is automatically built and tested by a CI server before merging into the main codebase.
- If issues are detected, the CI server blocks the merge and alerts the team for immediate fixes.
- Goal: Identify and address problematic changes as early as possible to maintain a stable codebase.
CI Process
Commit Phase
Reference: Martin Fowler on CI
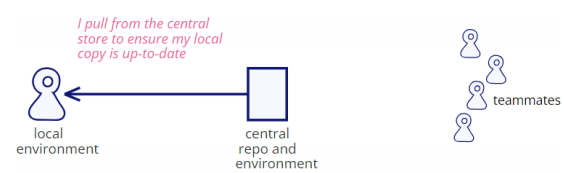
The CI process involves a structured sequence of steps to ensure code quality and integration:
-
Pull from Central Store
-
Make Changes

-
Pull Collaborators’ Changes
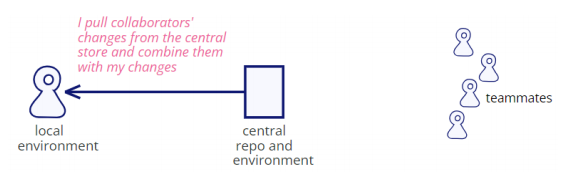
-
Rebuild and Test

-
Push to Central Repo

-
Central Build and Notification
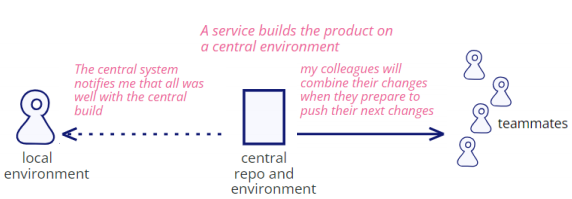
E.g.
1 | $ git fetch # optional |
CI Servers
-
Process
- Tasks automatically triggered by push
- Executed:
Compilation -> Linters -> Testing -> Artifact generation -> Security scan -> Deployment - Pass results to team
-
Benefits Compared to Local Builds:
- Consistency: Tests run in a clean, controlled environment identical for all developers.
- Automation: Eliminates manual steps, ensuring no tests or builds are skipped.
- Scalability: Supports large teams pushing changes continuously without conflicts.
- Immediate Feedback: Quickly notifies developers if their code or others’ breaks the build.
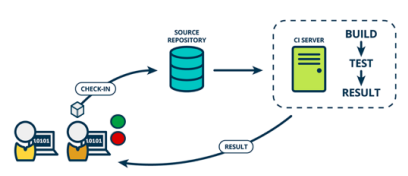
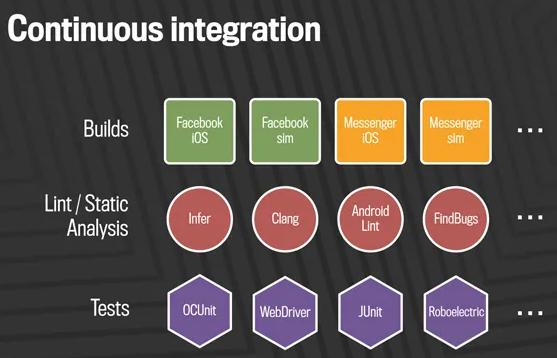
Example at Meta
- CI Stack Structure: Divided into three layers:
- Builds: Code committed to mobile master branches is built across all affected products.
- Static Analysis: Linters and static analysis tools run concurrently with builds to check code quality.
- Testing: Automated tests verify functionality before release on the main branch.
- Process: Ensures rigorous validation before code is merged.
Continuous Delivery
Environments
- Development Environment (开发环境): where developer modify and test code isolated to integrated codebase.
- Staging Environment (类生产环境): validate change, perform integration test and simulate real-world condition before deploying.
- Production Environment (生产环境): final deployment, backbone for service to customers.
Continuous Deployment
-
Continuous Delivery: extension of continuous integration, automatically deploys all code changes to a staging or production environment after the build stage.
- no constraint on release time (just suits your business requirements)
- deploy step is manual (picture shown below, orange part)
-
Continuous Deployment: every change that passes all stages of your production pipeline is released to your customers.
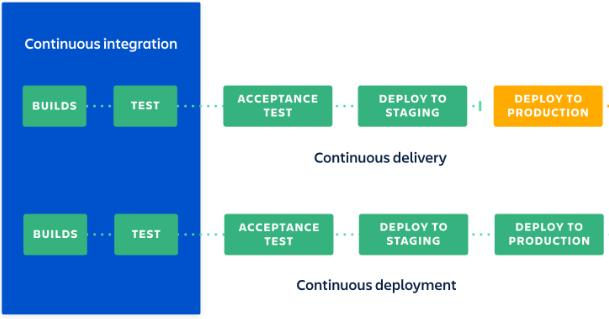
CI/CD Pipeline
- Definition: A series of automated steps that code changes go through from development to production.
Pipeline Breakdown
- Version control
- Source code
- Buildfile (as code)
- Documentation (as code)
- Infrastructure (as code)
- Artifact repositories
- Libraries, plugins, etc.
- Stage 1
- Commit to version control
- Trigger the build
- Compile
- Unit Test
- Doc
- Binary
- Generated binaries stored in the artifact repository
- Stage 2
- Automatically triggered by stage 1
- Run automated acceptance tests that take a long time to execute (e.g., integration testing, system/E2E testing)
- Can be executed on the staging environment
- Stage 3
- Basic: Ops team confirms and deploys the verified binary version to the production environment with one button click
- Optional:
- following stage 2, automatically deployed to staging environment for tool-aided non-functional tests, or manual UAT(user acceptance tests)
- Testers select proper version to release to product environment
Notes:
- In stage 2, configurations for the environment are version controlled
- Smoke test: minimal set of tests run on each build to test major functionalities, confirmation for QA team to proceed further software testing.
Brief Summary
-
CI/CD enables the application to be delivered reliably, quickly, and with high quality
-
CI/CD vs. Rapid Release: Sometimes same
- Deployment: available for use in staging/production environment
- Release: available for end-user.
-
Risk for CI/CD
- New version with problems should be rolled back
- Service temporarily down during upgrading.
Deployment Strategies
- Blue-Green Deployment:
- Uses two identical environments: Blue (current/old version) and Green (staging).
- New version is deployed to Green, tested, and then router is switched from Blue to Green.
- Benefits:
- Minimal downtime
- Rollback is easy and fast
- Drawbacks:
- Expensive: a redundant infrastructure
- Data consistency and integrity problems
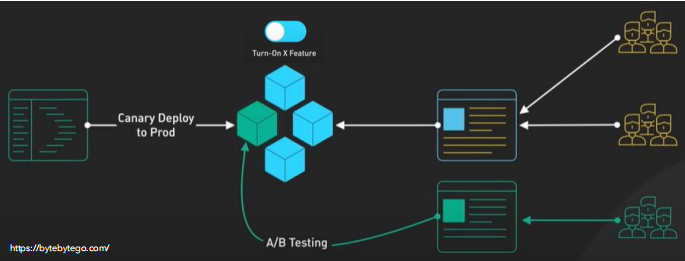
- Canary/Greyscale Deployment:
- Gradually rolls out the new version to a small subset of users (e.g., 2% of production).
- Monitors performance and issues before full deployment.
- Benefits:
- Test with real users
- If failure, affection scale is small
- Drawbacks:
- Complex traffic routing
- Strong monitoring of canaries required
- Canary users [内测用户] might not be representative
- Rolling Deployment:
- Updates servers incrementally, one or a few at a time.
- Benefits:
- No need for double resources
- Less infrastructure cost and maintenance efforts
- Minimal disruption
- Drawbacks:
- Significant latency between the moment you start deploying the new version and the moment it is all live
- Can’t control which users get the new version
- Inconsistent states among servers
Feature Toggle: Flexible use for different deployment strategies
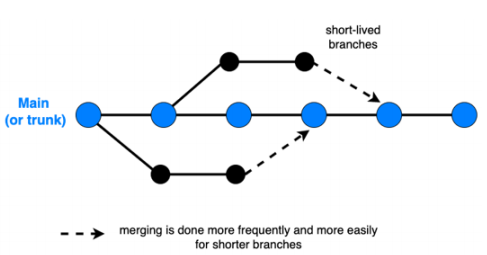
Branching Strategies
Trunk-Based Development & Release
- Approach: Developers work on a single branch (trunk) with frequent commits and integrations.
- Benefits: Simplifies merging, reduces conflicts, and ensures continuous integration.
- Drawbacks: Requires discipline to keep the trunk stable. Hard to rollback.
Trunk-Based Development & Branch-Based Release
- Benefit:
- devs on trunk and are less affected by release
- release won’t be affected by unfinished devs
- Drawback:
- too much branches !!
Branch-Based Development & Trunk-Based Release
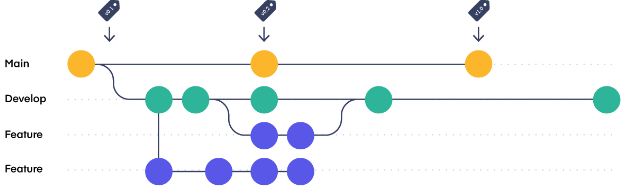
- Benefit:
- Flexible choices on features to release
- Fast, clean(not affect other branch) fix of bugs
- Drawbacks:
- Risk of big merges
- Delayed integration
Git Flow
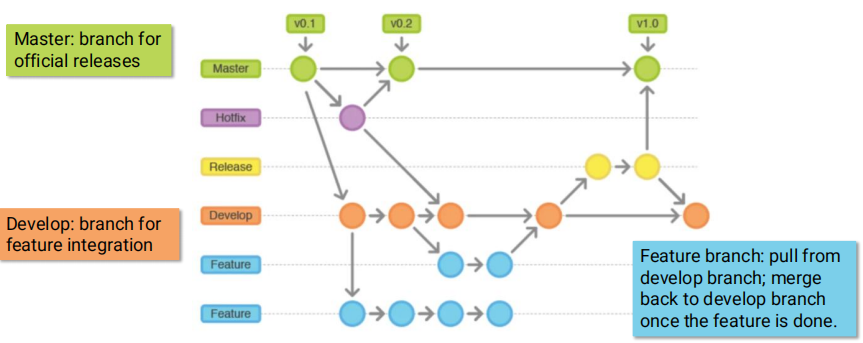
- Structure:
- Master: Holds official releases.
- Develop: Integrates features for the next release.
- Feature Branches: Used for developing individual features.
- Release Branches: Prepared for QA, merged back to master and develop after passing tests (optionally through Alpha/Beta phases).
- Hotfix Branches: Quick fixes for production issues.
- Benefits: Provides a structured workflow for managing releases.
- Drawbacks: Can become complex with many branches.
Case Study: CI/CD at Meta
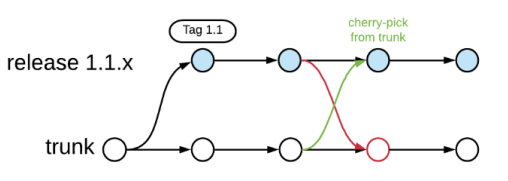
Before 2016
- Strategy: Master and release branch approach.
- Process: Engineers requested cherrypicks (tested changes) from master to the release branch for daily pushes.
- Reference: Facebook Engineering Blog
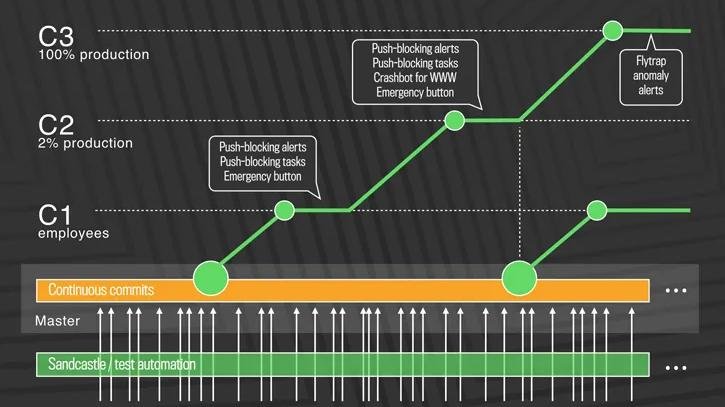
Current Process
- Three-Stage Rollout:
- C1 (Employees):
- Code diffs passing automated tests are pushed to Facebook employees.
- Push-blocking alerts flag regressions, and an emergency stop button halts further rollout.
- C2 (2% Production):
- If C1 succeeds, changes roll out to 2% of production.
- Monitors edge cases not caught in testing or employee use.
- C3 (100% Production):
- Rolls out to all users over a few hours.
- Flytrap tool aggregates user reports and alerts for anomalies.
- Team can stop the push if issues arise.
- C1 (Employees):
Lec 12. Cloud-Native Applications
Where we’re in?
Deploy & Infrastructure
Deploy
Deploying to a Single Server
- Process:
- SFTP(Secure File Transfer Protocol) code to the server.
- SSH into the server.
- Run the code.
Challenges of Deploying to Multiple Servers (50+)
-
Described as a “logistical, time-consuming nightmare”
-
Issues: Manual process for starting and monitoring processes on 50+ machines.
-
No automatic migration if a machine fails. (single-point issue)
-
Ad hoc monitoring of job progress.
-
Process interference leads to less-than-optimal scheduling and resource contention.
-
Solutions for Multi-Server Deployment
- Solution 1 (#1): Use reusable, robust, easy-to-maintain shell scripts for deployment
- Solution 2 (#2): Automate server status checks, export key health metrics, and detect anomalies
- Solution 3 (#2): Automatically handle anomalies (e.g., kill and reboot processes)
- Solution 4 (#3): Ensure processes run without interference from others
- Solution 5 (#3): Use a central service to pick unoccupied machines and deploy binaries
- Solution 6 (#3): Automate configuration parameter settings
It’s all about scale. Considering scale up(
2 vCPU|4 GB RAM -> 8 vCPU|16 GB RAM) or scale out (more CPU and RAM) ?
Infrastructure
Types of Scaling
- Scale Up (Vertical Scaling): Increase resources (e.g., CPU, RAM) on a single server.
- Scale Out (Horizontal Scaling): Add more servers/nodes and distribute workload.
Infrastructure Components
-
Computing:
- Hardware
- Software
-
Networks
-
Data Centers
-
Monitoring and Control Plane:
- 3 forms of infrastructure monitoring: hardware, network and application monitoring.
Complexities of Scaling Out (Inconvenience/drawbacks)
- Load Balancing: Distribute traffic evenly across servers.
- Configuration: Each new server needs proper setup (e.g., network, security).
- Monitoring/Troubleshooting: Harder with more servers.
- Maintenance: Increased workload for hardware/software updates.
Traditional On-Premise(本地部署) Infrastructure
- Organizations manage their own hardware/software in-house (servers, storage, networking).
- Drawbacks:
- Significant manual intervention
- Long release cycles
- Complex, time-consuming, and error-prone
Cloud-Native Applications
Cloud Computing
- Running applications on resources managed by cloud providers (e.g., AWS).
- Benefits:
- Frees teams from infrastructure management.
- Fast support of new resources.
- Effortless scaling.
- Cost-effective (pay-as-you-go pricing model).
Cloud-Native Applications
- Apps designed to exploit[利用] the scale, resiliency, and flexibility of cloud.
- Least Adopted Approaches:
- Processes: DevOps & CI/CD.
- Architecture: Microservices.
- Deployment: Containers.
- Practice: Infrastructure as Code (IaC).
Monolithic Architecture
- Entire application packaged as a single executable.
- Limitations:
- Inflexible for large teams/codebases.
- Difficult to scale efficiently.
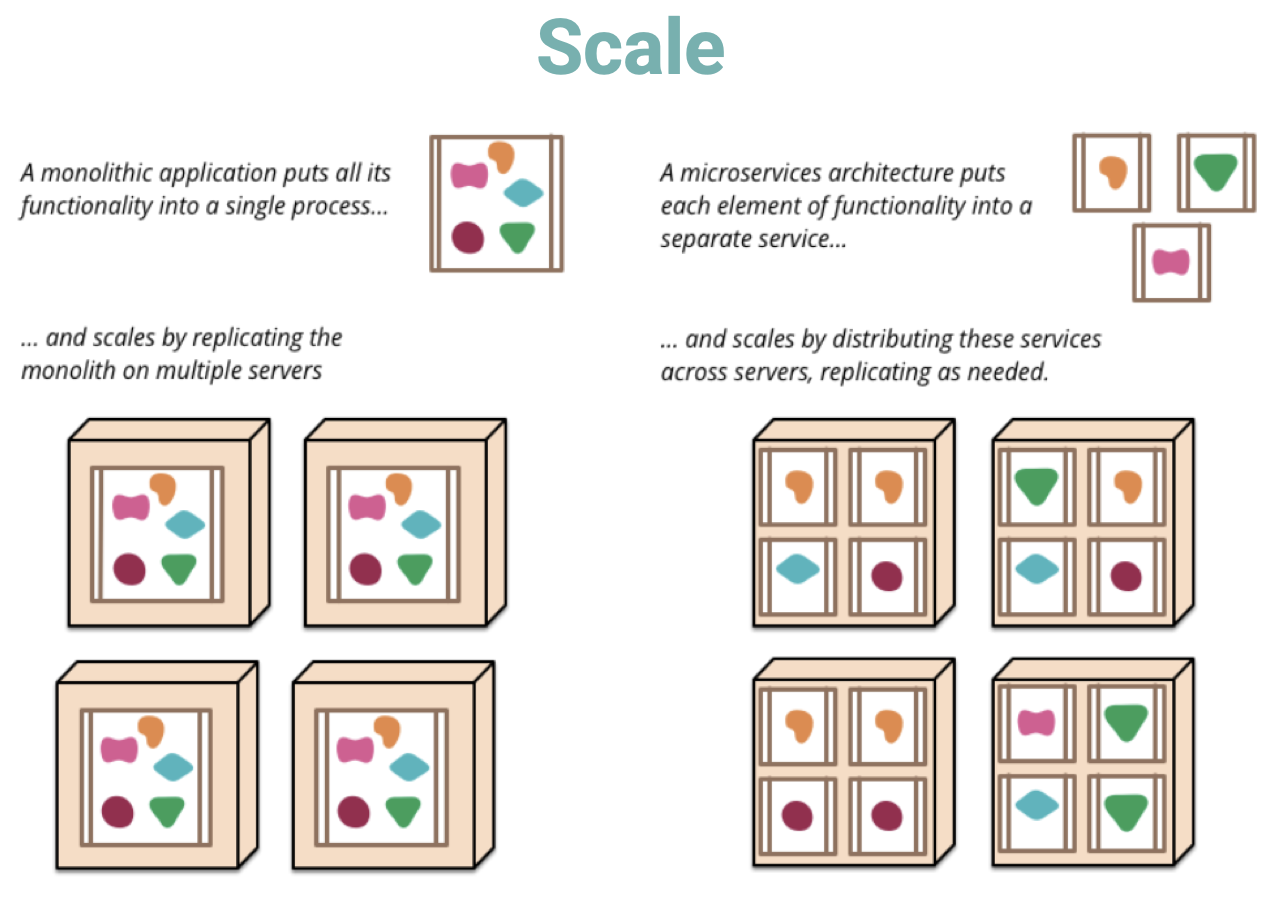
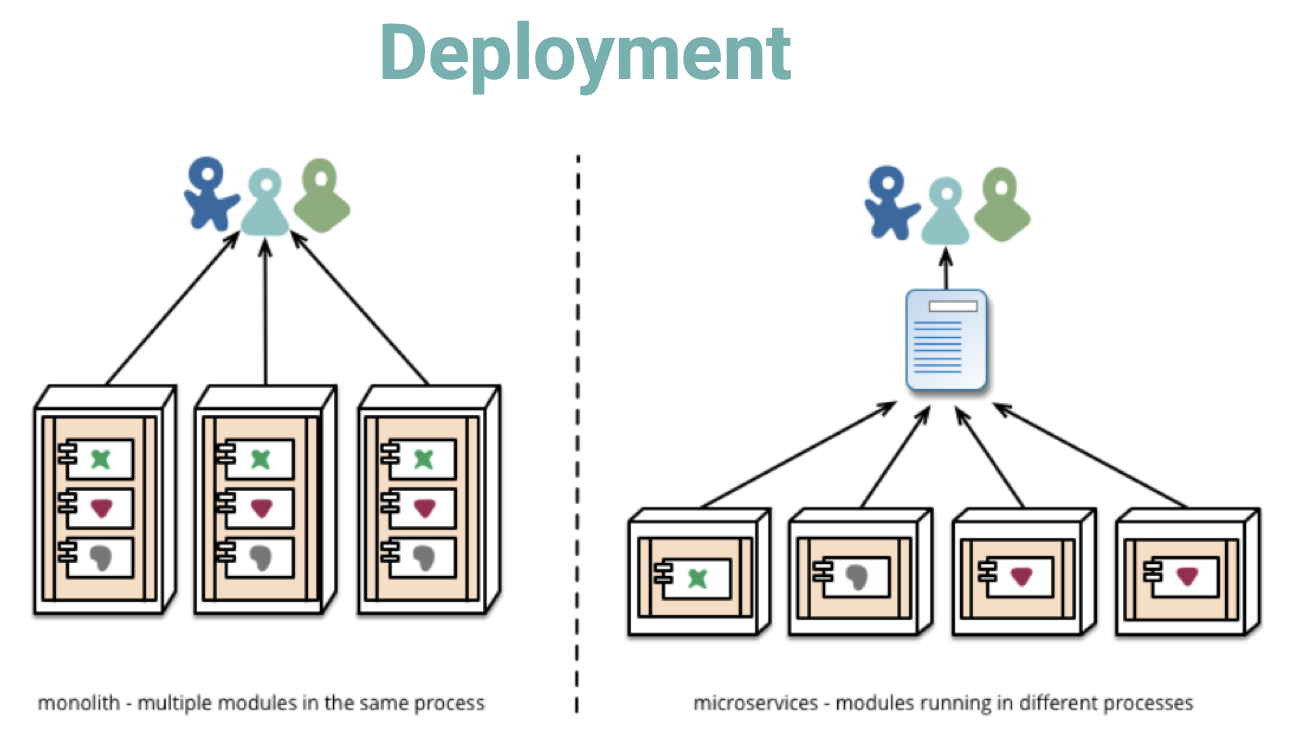
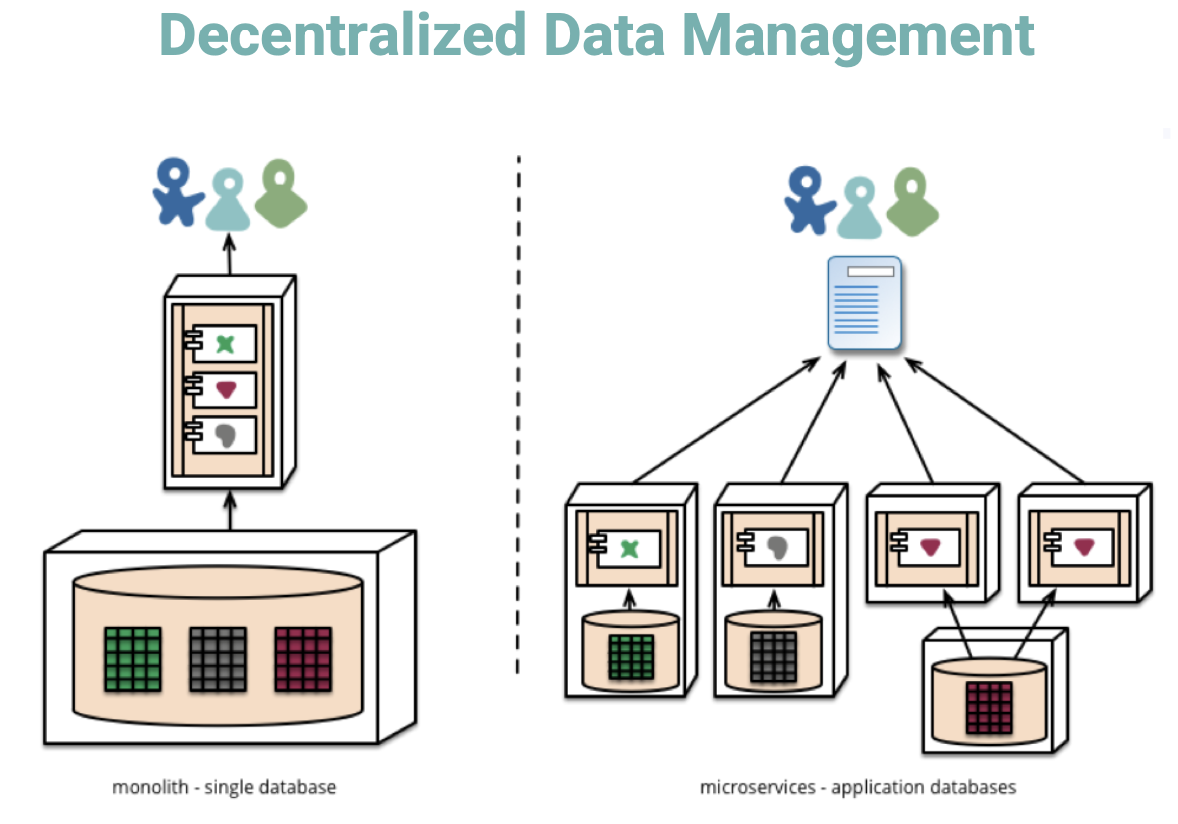
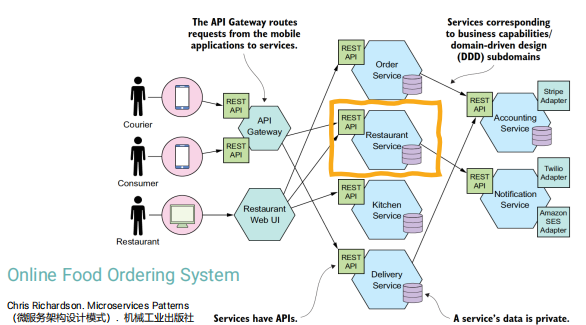
Microservices
-
Cloud-native apps composed of small, interdependent services.
- each service can be developed, managed and deployed independently.
-
Services communicate with each other by APIs. (e.g. REST)
-
Benefits:
- Better scalability.
- Flexibility.
- Easier maintenance.
An Example
Containers and Docker
Other Deploy Pattern
1. Language-Specific Package Pattern
- For example, Spring-boot-based Java application.
- Deployment pipeline builds an executable JAR file and deploys it into production.
- In production, each service instance is a JVM.
- Drawbacks:
- Lack of encapsulation of the tech stack: Ops team must know specific details of how to deploy each service, e.g., versions of
Tomcat,JettyorJREruntime. - Lack of isolation: one service failure will impact another
- Hard for resource controll: one service may consume all memory (starving other service instances)
- Manually allocation: determine resources assigned to service instances.
- Lack of encapsulation of the tech stack: Ops team must know specific details of how to deploy each service, e.g., versions of
2. Virtual Machine
- For example, AWS EC2
- Deployment pipeline creates an AMI(Amazon Machine Image), which has built environment
- All EC2 instances managed by AWS Auto Scaling Group.
- Drawbacks:
- Low resource utilization: each service needs entire VM
- Slow deployment: take time to build VM, move VM image over network and boot OS running inside VM.
Therefore, we need a more efficient way other than LS Package Pattern and VM.
Containers
- Def. lightweight and portable unit of software that packages an application and its dependencies together in a single environment.
- Use VM basis: each container has isolated environment. (but a single VM can run multiple containers)
- You can specify CPU, memory resources and I/O resources.
- Containers communicate using standard network (each of them has unique IP addresses)
Docker
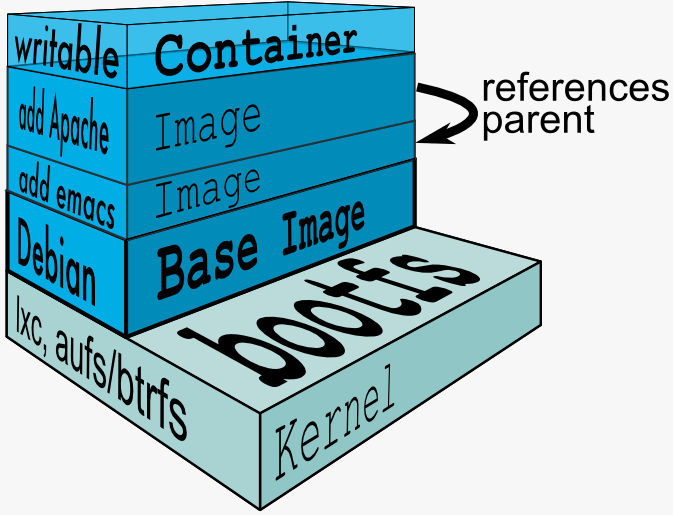
Docker Images: multi-layers
- Kernel: Host machine’s kernel
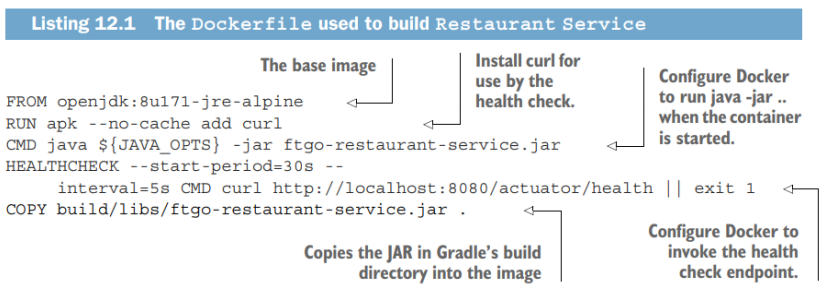
- Base image (
FROMinDockerfile):- Different Linux distribution (e.g. Debian, Ubuntu)
- Various pre-installed software images (e.g. OpenJDK)
- or a blank image
- Build-time instructions in Dockerfile
RUN: Executes shell commands (e.g. install packages)ADD/``COPY`: Copies files into the imageWORKDIR
In docker build time, each instruction creates a read-only layer on top of one another
- Runtime instructions in Dockerfile:
CMD,ENTRYPOINT - Each time Docker launches a container from an image, it adds a thin writable layer, known as the container layer, which stores all changes to the container throughout its runtime (e.g. writing files or logs).
- Multiple containers write changes locally and independently, but share access to the same underlying level of a Docker image.
Dockerfile
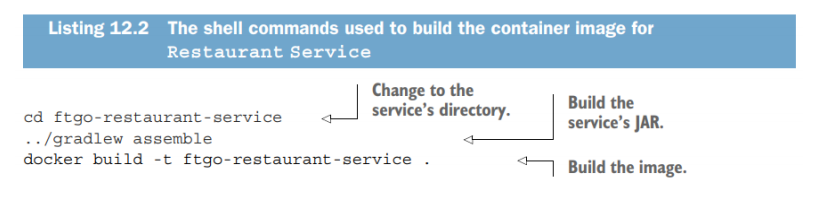
Final step of build process is to push Docker image to a registry/hub. (similar to Java Maven repo for Java libraries)
- then run the container:

Container Orchestration
Orchestration(编排) Purpose
- Automates & manage:
- Deploying containers across servers.
- Configuration, scheduling, resource allocation.
- Scaling/removing containers based on demand.
- Monitoring health and restarting failed containers, etc.
Tools
- Docker Swarm.
- Kubernetes (K8s).
Kubernetes Architecture
- Cluster: Control plane + worker nodes.
- Control Plane (Master): Manages scheduling, scaling, updates.
- Worker Nodes: Run containerized applications.
- Pod: Smallest deployable unit, hosts containers.
- Kubelet: Manages pods on nodes.
- Container Runtime (e.g., Docker): Runs containers.
- Kube-proxy: Handles networking and load balancing.
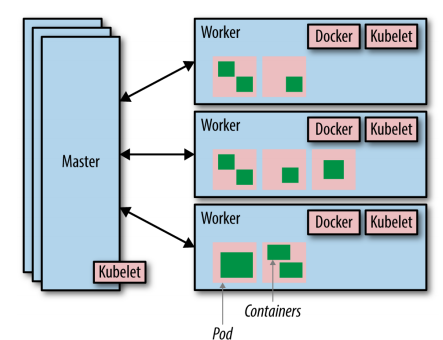
Kubernetes YAML Files
- Define desired state (e.g., replicas, container specs).
K8S Deployment Strategies
- Rolling Strategy: Gradual updates.
- Recreate: Terminate all instances, then recreate with new version.
Define in YAML
spec.strategy.type, has typeRollingUpdateandRecreate
Infrastructure as Code (IaC)
- Define/manage infrastructure (servers, networks) using code.
- Stored in version control (e.g., Git), executed via automation tools.
- Benefits:
- Consistency.
- Repeatability.
- Applies software development best practices.
Example: Jenkins Pipeline
- Steps:
- Configure GitHub webhook to notify Jenkins on push.
- Jenkins downloads updates.
- Executes tasks: build (Maven), test (JUnit), build/push Docker image.
- Deploys to Kubernetes cluster.
- Kubernetes pulls images from registry.
Monitoring and Cloud Service Providers
- Monitoring: Tools track Kubernetes cluster and application health.
- Cloud Providers: AWS, Google Cloud, Huawei Cloud offer managed CI/CD services.
Lec 13. Software Evolution
Where we’re in?
Maintenance
Software Maintenance
Components
- Bug/Vulnerabilities fix
- Environmental adaptation
- Functionality addition
Maintainability
Measurement
- Num of requests for corrective maintenance
- Average time required for impact analysis
- Average time taken to implement a change request
Technical Debt
-
Def. refers to the long-term cost of making short-term or suboptimal decisions in software design
-
Types
- Quick and dirty fixes: minimal testing, code rushed to DDL.
- Well-intentioned past decisions that don’t scale well anymore: as business evolves, system becomes bottleneck or liability
-
Case Study: Overflow
- Split codebases: The code for handling user login and registration was split across two different codebases
- Functional limitations: Email addresses were stored in two separate databases; users couldn’t reset the password with their new email addresses
- Outdated Dependencies: CareersAuth had not been updated for several years, necessitating time-consuming updates to various dependencies to make it operational on a local development environment
Refactoring
- Def. To improves the internal structure while preserving external behavior
- Why?
- Improve design of software; simplify code by removing unnecessary complexity or duplication
- find bugs and make code robust; increase readability and productivity
- reduce cost of software maintenance; prepare for future customization
- When?
- Rule for Three: same thing happens the third time
- when new feature is hard to integrate with existing code
- when bug is hard to trace, refactor first to make code more clear
- during code review (last chance)
- What to refactor?
- a warning sign of your code
- a surface indication that usually corresponds to a deeper problem in the code or system
- Code that doesn’t smell good / doesn’t feel right (actually not just a feeling, keep going)
Types of Code Smells
- Bloaters (代码臃肿)
- Long method: make method less understandable
- Long parameter list: too much param leads to error-prone (example shown below)
1 | // long param list |
- OO(object-oriented) Abusers
- Violation of the Liskov Substitution Principle: a subclass inherits from a parent class, but the subclass doesn’t need all behaviors of parent class. (Inheritance doesn’t make sense)
- Refactor: replace inheritance with delegation [分配?], i.e., put the behaviors that subclass refuses off the parent class.
1 | // before |
- Change Preventers
- You have to change much when you only need to change one. [代码重复]
- Violation of the Single Responsibility Principle
- Refactor: extract method [代码复用]
- Couplers
- Feature envy: 类方法大量使用另一个类的数据
- Inappropriate intimacy: 类使用另一个类的 fields 和方法
- Message chains: 方法链式调用
- Middle man: 中间类“行为”太少,没有存在必要
- Dispensibles: something whose disappearance would make code cleaner, more efficient and more understandable
- Duplicate code
- Dead code (unused and obsolete code)
- Lazy class (classes that don’t do enough to earn your attention)
Code smells are usually not bugs, and don’t always indicate a problem. But improving it can benefit maintenance.
Re-Architecting
-
When to re-architecting Monolithics?
- Find out problems: slow delivery, buggy releases or poor scalability
- and problems remain after trying refactor or other solutions…
- then re-architect to Microservices
-
Strategies
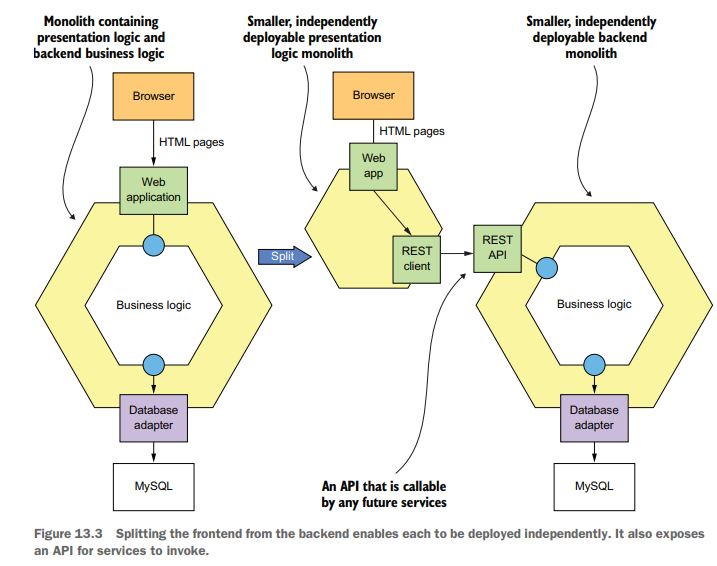
- New features as services
- Separate the presentation tier from backend
- Break up monolithic by extracting functionality into services
About Sol.2, here’s a figure:
Software Evolution
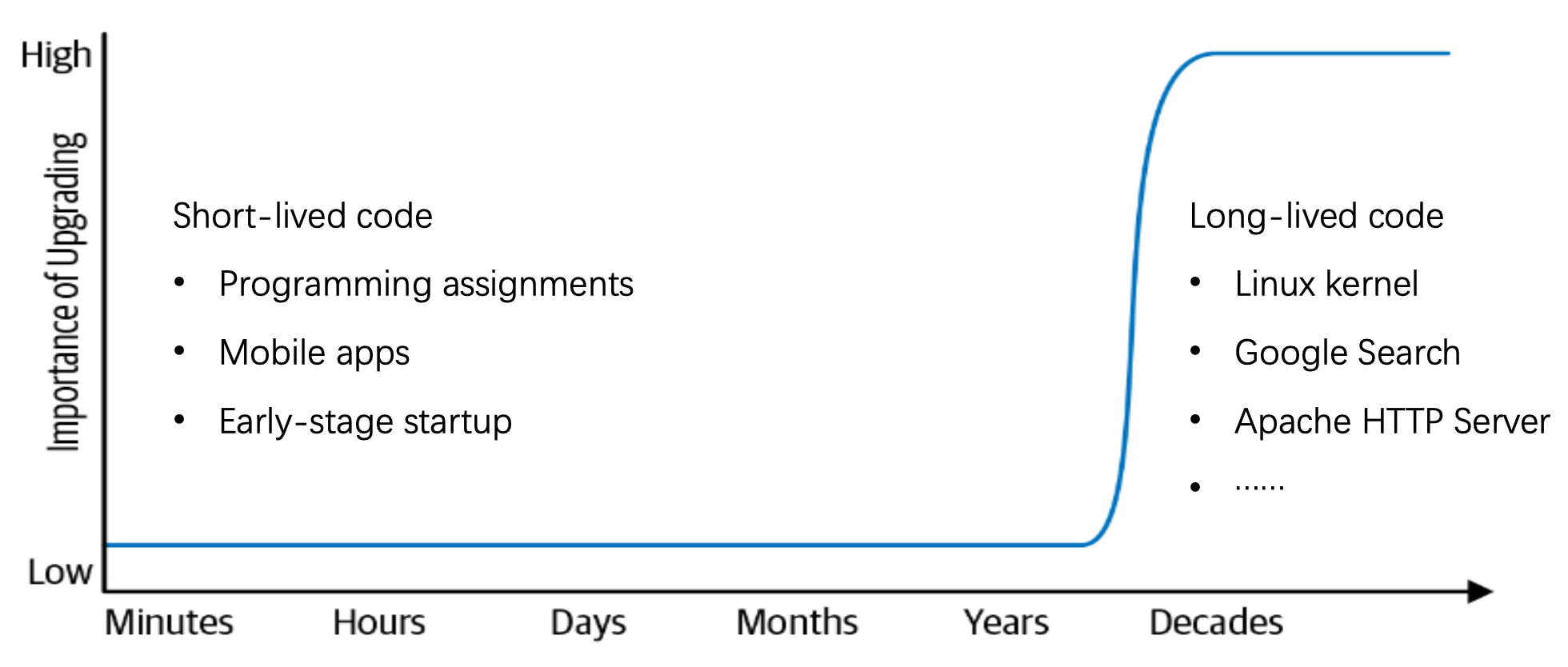
Why software evolution costly?
- needs to migrate to new platforms, for different machines and OS, and meet new requirements
- complexity grows.
- people (DevOps teams) come and go
Legacy Systems
-
Definition: Outdated but operational software/hardware (e.g., Windows XP in ATMs)
-
Risks of replacing legacy code:
Risk Factor Impact Implicit Business Rules Critical logic undocumented Structural Decay Hard to understand/extend Obsolete[过时] Technologies COBOL skills shortage Integration Complexity High failure risk (e.g., Southwest Airlines meltdown)
Legacy System Decisions
| Business Value | System Quality | Strategy |
|---|---|---|
| Low | Low | Abandon |
| High | Low | Modernize |
| Low | High | Maintain (abandon if changes costly) |
| High | High | Continue maintenance |
-
Modernization Strategies
- Re-host, Re-platform: migrate to a new platform or infrastructure
- Refactor
- Re-architect
- Replace: part or all of the system
- Re-engineer/Rebuild
-
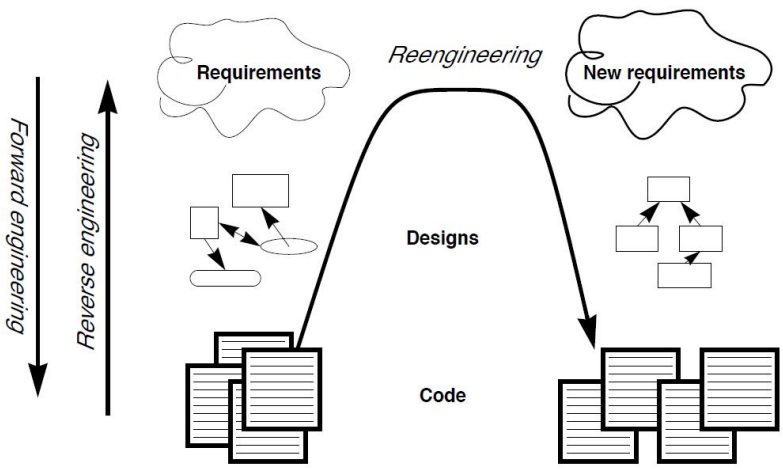
Re-engineer Process
- Reverse engineering: legacy code $\to$ old design $\to$ old requirements
- System transformation: new requirements
- Forward engineering: new requirements $\to$ new design $\to$ new code
Deprecation
-
When to Deprecate: Demonstrably obsolete systems with replacements (not just “old”)
-
Elegant Strategies:
Strategy Tools/Process Purpose Dependency Discovery Static analysis, Logging Identify users/usages Warning Flags @DeprecatedJava annotationsPrevent new usage Sunset Periods 6-12 month phased support Allow migration time Automated Migration Code update tools, Test suites Ensure functionality -
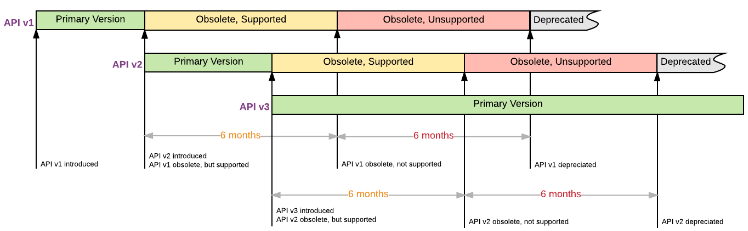
Chart about Sunset Period: