分布式存储系统
Introduction
Before Learning
The following lists some knowledge that you should know before in my viewpoint.
- Preliminaries
- Principles of Computer Organization: Memory and computer architecture(e.g. von neumann)
- Principles of Database
- Computer Networks: We may learn network-attached storage
- Operating Systems: especially
Linuxfile system and memory scheduling
Brief History of DSS
- DAS (Direct-Attached Storage): using cables (e.g. SCSI) to connect to server internal bus (one-storage-to-one-host) >> non-shared, poor scalability
- FAS (Fabric-Attached Storage):
- NAS (Network-Attached Storage): shared network storage providing data storage service >> I/O bottleneck
- SAN (Storage Area Network): access data through dedicated Fibre Channel(光纤) switches, protocol like ISCSI, FC
Issues: 1. Performance grows by controller, scalability drop down at
PBlevel data; 2. time-consuming in transferring data from old device.
Distributed Storage
Def. Distributed Storage is to separate all the data into multiple storage servers, which form one virtual storage device.
Benefits
- improve system reliability
- accelerate I/O efficiency
- better scalability
- support hierarchical storage
Metrics to measure storage performance
- Bandwidth: theoretic throughput (data transferred per second)
- Delay: time for a specific operation
- Throughput: data transferred per second
- IOPS (Input/Output Operations Per Second)
Measurement Tools
- FIO(flexible I/O tester): simulate I/O overhead in different cases, supporting random read/write, asynchronous I/O, etc.
Software Defined Systems
- Stem from Google File System (Google, 2003)
- Core: Using software only to manage x86 machines to form a distributed system
- Separate Meta and Data, where Meta is the core component in the system to manage plenty of chunk server(节点)
Two SDS Architectures: Centralized vs. Distributed
Similarity
- Both aim at allocating data equally into all disks
- of course, distributed systems have all disks in multiple nodes(chunk servers), but the centralized one have them in one place.
Difference
| Centralized Storage | Distributed Storage | |
|---|---|---|
| Protocol | block, file | block, file, object |
| Scene | Database, Virtualization | Database, Virtualization, Big Data, plenty of unstructured data |
| Scalability | Controller: 2-16, SSD: 1-12 | 1024 nodes |
| Performance | low delay | high concurrency |
| Reliability | RAID + BBU bateries | multi-copy |
| Locate Algorithm | Strip algorithm / Pseudo random | Pseudo random CRUSH algorithm |
| Application(Instances) | Google GFS, HDFS | Ceph |
Some of the concept mentioned above:
Block storage, file storage and object storage
| Block storage | File storage | |
|---|---|---|
| Principle | divide disk into blocks, then format blocks into an LUN(logic unit number) and mounted to server OS as a disk | store data by hierarchical directory,and accessed by file path |
| Protocols | iSCSI, FC(fabric channel) | NFS(network file system) |
| Pros | low delay, high IOPS | multi-user access at the same time |
- Object storage: combine advantages of block and file
- using key-value for management, easy for locating and operating data
- have no directory, resulting in high retrieving performance
Key difference: they serve different client
Block storage: systems who read/write at block device
File storage: human
Object storage: others such as software
Recall: DAS, NAS and SAN. DAS, SAN use block storage, while NAS use file storage.
Strip algorithm & CRUSH algorithm
Strip algorithm: divide data into strips, and store them in different disks. They seems continuous logically, but phisically they are not.
- Concept
- Strip length: describes how many blocks are stored in one strip
- Strip depth: describes how many strips are stored in one disk
- Advantage:
- high performance: parallel read/write
- high capacity: data can be stored in multiple disks
- high reliability: applying
RAIDto protect data
CRUSH(Controlled Replication Under Scalable Hashing): a pseudo-random algorithm to locate data in distributed storage system.
Since it’s commonly used in
Ceph, we will learn it in detail in the next section
Network Protocols of Distributed Block Storage
| Protocol | Description |
|---|---|
| iSCSI(Internet Small Computer System Interface) | SCSI is a protocol connecting host and external device(but also an interface). ISCSI can be served as a protocol in application layer(apply Ethernet to encapsulate SCSI commands and transfer by TCP) ISCSI is under CS architecture |
| NVMe-oF(NVMe over Fabrics) | Extension of NVMe protocol(an intra-server protocol of SSD) over network |
| RDMA(Remote Direct Memory Access) | A technology that allows data to be transferred from the memory of one computer to the memory of another without involving the CPU, cache, or operating system of either computer |
| RDMA+NVMe-oF | a popular usage of RDMA to accelerate NVMe over Fabrics |
Storage Cluster
- Cluster: a group of servers that work together to provide a service, handling the large visiting, high parallel and sea of data.
- 2 sub-class: load balance & distributed
- difference on how the multiple servers cooperate
Load Balance
- DNS Load Balance: configure multiple IPs for one domain name, and the DNS server will return one of them randomly(properly)
- HTTP Load Balance: Calculate a true address of web server by http request, write it into the response header and return to browser(host)
- IP Load Balance: modify target IP address in network layer
- Link Load Balance: modify target MAC address in data link layer
- Hybrid Load Balance
Load Balance Algorithms
| Algorithm | Description |
|---|---|
| Round Robin | distribute requests evenly to all servers |
| Least Connections | distribute requests to the server with the least connections |
| IP Hash | use the hash value of client IP address to determine which server to send the request |
| Random | randomly select a server to send the request |
| Weighted | algorithm above with weighed score |
Distributed Cluster
- Def. Applying multiple servers, each of which has different roles, to provide a service.
- Applications:
- Distributed applications & services
- Deployment of distributed static resources
- Distributed data & storage
- Distributed computing
High Availability
- Def. A system that can continue to provide services even when some of its components fail.
Distributed Systems
Ceph
- Published in 2004
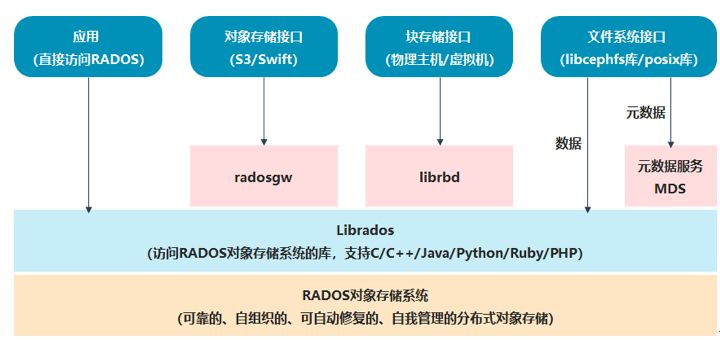
RADOS: Reliable Autonomic Distributed Object StoreLibRados: a library to access RADOS(support for C/C++/Python)- three API based on
LibRados:RadosGW: object storage API, compatible with S3 and OpenStack SwiftLibRBD: block storage API, compatible with iSCSIMDS: file system API, compatible with NFS and CIFS
Core Components(Services)
Monitor: monitor the health of the cluster, store cluster map and configuration(e.g. OSD maps, CRUSH maps)Client: provide APIs to access RADOS, load balance for nodesMDS(Metadata Server): manage metadata/directories of filesOSD(Object Storage Daemon): store data, handle read/write requests, replicate data, recover data
Allocation of Resources: CRUSH
- data divided into objects
- each object is hash-projected into one Placement Group(PG), i.e., one PG contains multiple objects
- CRUSH algorithm used to map PGs to OSDs(if multiple copies, see following assumption of three replicas)
- Client’s PG is mapped to the primary OSD
- the primary OSD finds the other two OSDs by CRUSH algorithm
- the primary OSD sends the data to the other two OSDs
- the other two OSDs store the data, and return
ACKto the primary OSD - the primary OSD writes the data to its local disk, and returns
ACKto the client
Pros and Cons
- Pros:
- High performance: parallel read/write, low latency
- Decentralized: no single point of failure, no bottleneck
- High consistency:
ACKreturned only after all replicas are stored, which suits occasions that read operations are much more than write operations
- Cons
- Poor expansion: adding new OSDs requires rebalancing data, which is time-consuming
GFS(Google File System)
- Components
- Master Server: manages metadata, namespace, and access control
- Chunk Server: stores data chunks(64M by default), handles read/write requests
- Client: provides APIs to access GFS, caches metadata
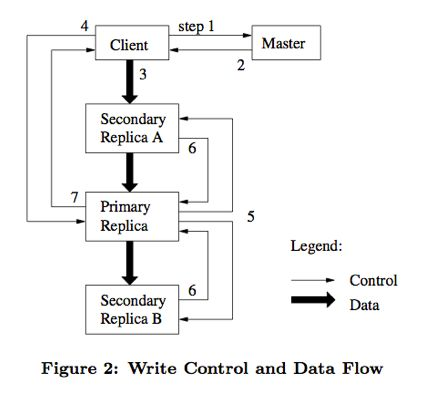
- In data read/write, GFS split data flow and control flow by lease mechanism
- Data flow: client push data to each chunk server
- Control flow: client contact primary replica, who decides which chunk server to write data. Unless the primary replica is down, the client will not contact master.
Pros and Cons
- Pros:
- suitable for large files, high throughput
- high performance: cached metadata in client, parallel read/write(by pre-read)
- high reliability: master backup at checkpoint, chunk replication
- Cons:
- single point: master server